


.png&customEmojiId=1f90aba3-9a4b-809e-9976-007a0d7cef6d&width=250)
플랫폼 특성 파악하기
분석에 앞서, 먼저 플랫폼의 전체적인 특성을 이해하기 위해 상품 가격대(price_band)와 상품 카테고리(product_category) 분포를 확인하였다.
이를 통해 해당 플랫폼이 어떤 가격 중심의 제품을 주로 다루고 있는지, 그리고 주요 판매 상품군이 무엇인지를 파악할 수 있을 것이다.
특정 가격대에 사용자가 몰려 있다면 이 플랫폼의 주요 타겟층과 마케팅 전략 방향도 유추해볼 수 있다는 생각이 들었다.
상품 카테고리 파악 - 패션 플랫폼
df = pd.read_csv("df4.csv")
price_band_counts = df['price_band'].value_counts().reset_index()
price_band_counts.columns = ['price_band', 'count']
price_band_counts
Python
복사

상품 카테고리
가격 분포 - 중저가에 분포
df = pd.read_csv("df4.csv")
price_band_counts = df['price_band'].value_counts().reset_index()
price_band_counts.columns = ['price_band', 'count']
price_band_counts
Python
복사
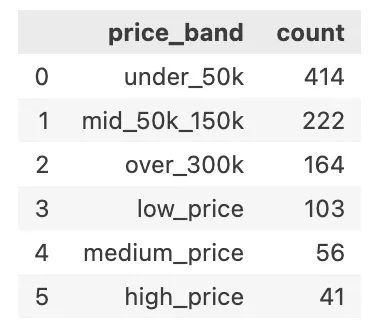
가격 분포
많은 가격 타입 2가지 + 유저 타입별 + 유입 경로별로 이탈률 구하기
다음으로는 유저의 행동 흐름 중 '장바구니에 담기 전 이탈' 여부를 기준으로 user_type과 traffic_source 조합별로 이탈률을 계산하였다.
또한 플랫폼 특성 중 하나인 중저가 가격대를 설정하여 보다 구체적인 행동 특성을 파악하려고 시도했다!
(먼저 유저 타입 별 + 유입 경로별로 이탈률을 구해보았으나 유의미하게 이탈률이 차이가 나지 않아 좀 더 구체화함)
가격 타입별 + 유저 타입별 + 유입 경로별로 이탈률 구하기
df['is_churned'] = df['add_to_cart'] == 'No'
filtered_df = df[df['price_band'].isin(['under_50k', 'mid_50k_150k'])]
# user_type + traffic_source 조합 그룹화하기
summary = filtered_df.groupby(['price_band', 'user_type', 'traffic_source']).agg(
total_users=('user_id', 'count'),
churned_users=('is_churned', 'sum')
).reset_index()
summary['churn_rate'] = summary['churned_users'] * 100 / summary['total_users']
summary
Python
복사

구체적으로 조합하니 이탈률이 유의미하게 차이가 난다.

행동 특성 패턴 파악하기
마지막으로는 review_clicked와 discount_exposed 여부를 조합하여, 유저의 행동 변화에 영향을 주는 요인을 보다 구체적으로 분석하였다.
또한, 동일한 조건에서 유사한 행동을 보인 유저 수를 함께 집계하여 한정적인 정보 안에서도 최대한 객관적으로 유저의 행동 특성을 파악할 수 있도록 수치화하였다.
이를 통해 정성적인 추정이 아닌, 실제 행동 데이터 기반의 페르소나 설정이 가능하도록 접근하였다.
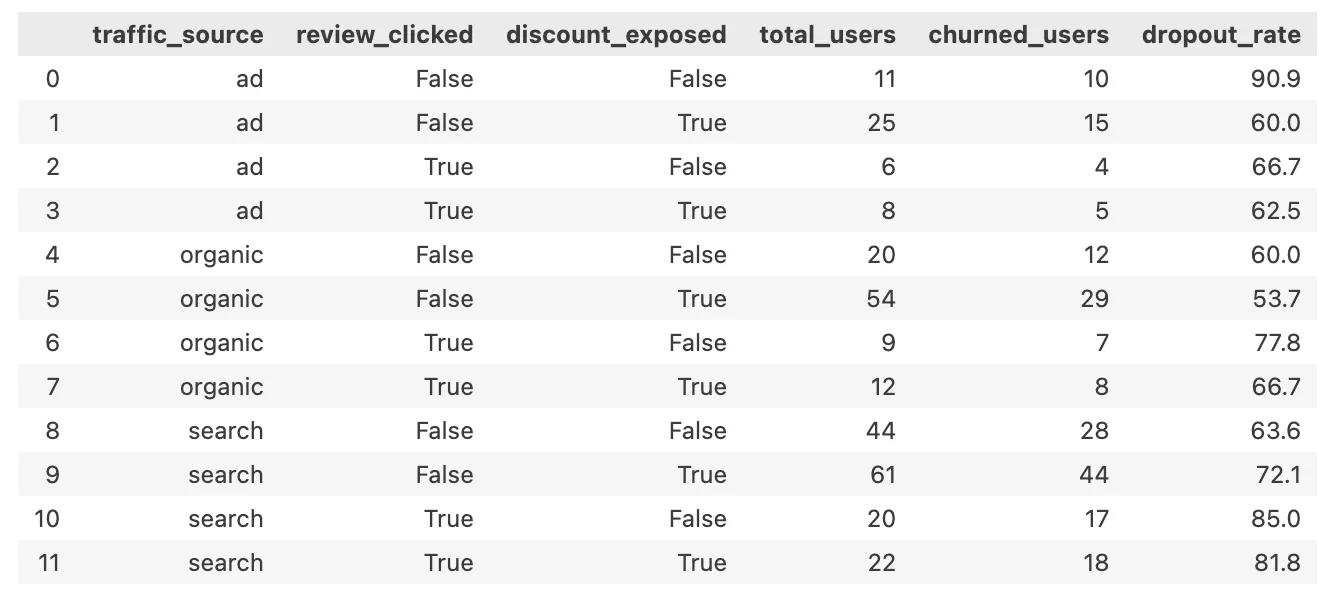
new(under_50k)+ 유입 경로별 + 리뷰 클릭 여부 + 할인 노출 여부
df_filtered = df[
(df['user_type'] == 'new') &
(df['price_band'] == 'under_50k')
]
no_df = df_filtered[df_filtered['add_to_cart'] == 'No']
no_counts = no_df.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
total_counts = df_filtered.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
summary = pd.DataFrame({'total_users': total_counts,'churned_users': no_counts}).fillna(0).reset_index()
summary['dropout_rate'] = (summary['churned_users'] / summary['total_users'] * 100).round(1)
Python
복사
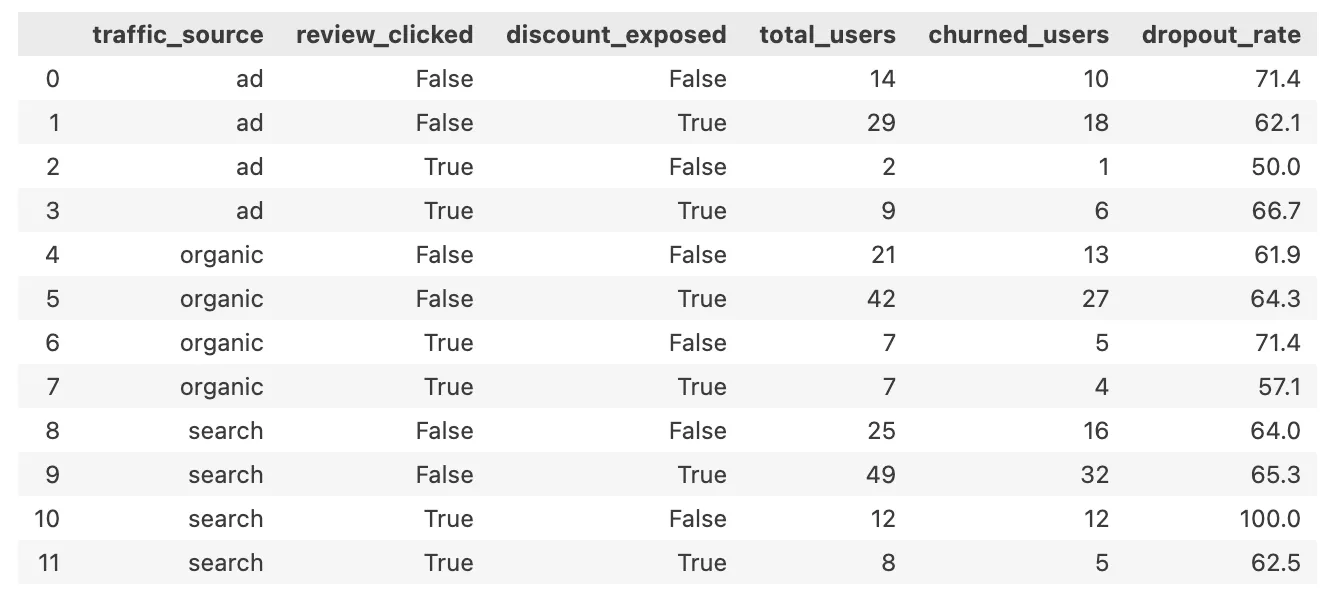
returning(under_50k)+ 유입 경로별 + 리뷰 클릭 여부 + 할인 노출 여부
df_filtered = df[
(df['user_type'] == 'returning') &
(df['price_band'] == 'under_50k')
]
no_df = df_filtered[df_filtered['add_to_cart'] == 'No']
no_counts = no_df.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
total_counts = df_filtered.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
summary = pd.DataFrame({'total_users': total_counts,'churned_users': no_counts}).fillna(0).reset_index()
summary['dropout_rate'] = (summary['churned_users'] / summary['total_users'] * 100).round(1)
Python
복사
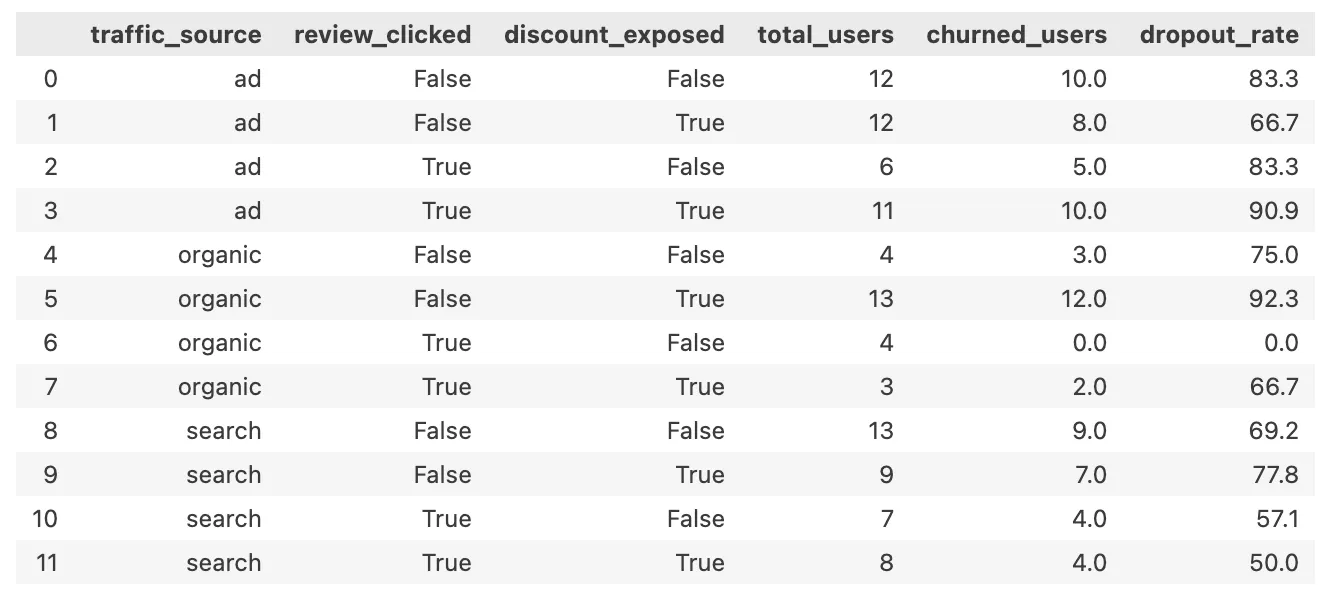
new(mid_50k_150k)+ 유입 경로별 + 리뷰 클릭 여부 + 할인 노출 여부
df_filtered = df[
(df['user_type'] == 'new') &
(df['price_band'] == 'mid_50k_150k')]
no_df = df_filtered[df_filtered['add_to_cart'] == 'No']
no_counts = no_df.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
total_counts = df_filtered.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
summary = pd.DataFrame({'total_users': total_counts,'churned_users': no_counts}).fillna(0).reset_index()
summary['dropout_rate'] = (summary['churned_users'] / summary['total_users'] * 100).round(1)
summary
Python
복사

returning(mid_50k_150k)+ 유입 경로별 + 리뷰 클릭 여부 + 할인 노출 여부
df_filtered = df[
(df['user_type'] == 'returning') &
(df['price_band'] == 'mid_50k_150k')]
no_df = df_filtered[df_filtered['add_to_cart'] == 'No']
no_counts = no_df.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
total_counts = df_filtered.groupby(['traffic_source', 'review_clicked', 'discount_exposed'])['user_id'].count()
summary = pd.DataFrame({'total_users': total_counts,'churned_users': no_counts}).fillna(0).reset_index()
summary['dropout_rate'] = (summary['churned_users'] / summary['total_users'] * 100).round(1)
Python
복사

최종 페르소나 설정
같은 행동을 보인 유저가 많다고 해서 그 자체만으로 페르소나가 되는 건 아니다.
유저가 어떤 채널을 통해 들어왔고, 어떤 유형인지(신규인지, 기존인지)까지 함께 봐야 현실적인 페르소나를 구성할 수 있다.
1.
신규 유저는 광고나 검색을 통해 유입되는 경향이 강하므로, 해당 경로 내에서 이탈률과 행동 특성이 뚜렷한 조합을 우선적으로 고려하여 구성
2.
기존 유저는 자연 유입이나 리타겟 광고 등을 통해 재방문하는 경우가 많으므로 재구매 전환에 영향을 주는 조건을 중심으로 페르소나를 구성
동일한 행동 특성을 가진 유저 수 + 채널-유형 간의 맥락을 고려한 혼합으로 페르소나를 구성하는 것이다.
아래는 미리 정리해둔 행동 특성 후보군이다.
내일 팀원들과 함께 이 중 여러가지 조건을 골라 기본적인 가설을 만든 뒤, 각자 해당 조합에 맞춰 구체적인 분석 주제를 정해볼 계획이다.
동일 행동이 많은 유저를 가장 큰 기준으로 하여 구성하였는데, 놀랍게도 리뷰를 클릭하지 않은 행동 패턴들이 많은 것도 유의미한 인사이트 중 하나다.
번호 | 가격대 | 유저 유형 | 유입 경로 | 리뷰 클릭 | 할인 노출 | 이탈률 (%) | 유저 수 |
1 | under_50k | new | ad | | | 90.9 | 11 |
2 | under_50k | new | ad | | | 60.0 | 25 |
3 | under_50k | new | organic | | | 53.7 | 54 |
4 | under_50k | new | search | | | 63.6 | 44 |
5 | under_50k | new | search | | | 72.1 | 61 |
6 | under_50k | returning | ad | | | 71.4 | 29 |
7 | under_50k | returning | organic | | | 64.3 | 42 |
8 | under_50k | returning | search | | | 65.3 | 49 |
9 | mid_50k_150k | new | ad | | | 100.0 | 16 |
10 | mid_50k_150k | new | ad | | | 81.2 | 16 |
11 | mid_50k_150k | new | search | | | 78.0 | 41 |
12 | mid_50k_150k | new | search | | | 76.7 | 30 |
13 | mid_50k_150k | returning | ad | | | 83.3 | 12 |
14 | mid_50k_150k | returning | organic | | | 92.3 | 13 |