



가설 설정 및 검증
e-Reader기를 사용하는 사람이 이탈률이 적을 것이다. 승인님
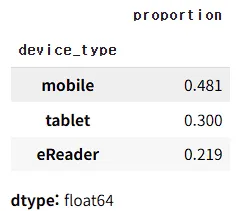
## e리더기 사용
df_merged['device_type'].value_counts(normalize = True)
Python
복사
##구독플랜의 종류와 함께 확인해봄
df_merged.groupby(['subscription_plan','device_type']).count() / df_merged.count() *100
Python
복사
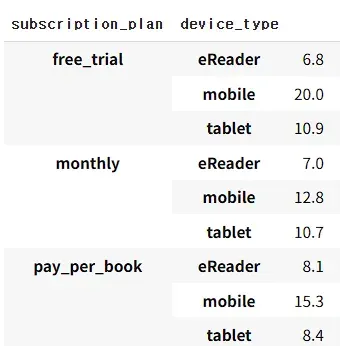
이탈한 대상 1000명 중에 e리더기 비율이 가장 낮다.
(e리더기 사용자 자체가 적을 가능성이 있다 )
e리더기를 구매한 사용자는 완독할 가능성이 크다
e리더기 사용자들의 행동 패턴 분석하여 다른 기기에 적용해볼 수 있다.
경제/시사 장르를 읽는 사람들의 이탈률이 높을 것이다. 승인님
df_merged['genre'].value_counts(normalize=True)
Python
복사

df_merged['exit_po_group'] = pd.cut(df_merged['exit_position_numeric'], ##이탈한 위치를 나눔
bins=[0,25,50,75,100],
labels=['25% 이하', '25~49%', '50~74%', '75% 이상'],
right = True)
df_merged[df_merged['genre'] =='경제/시사'].value_counts('exit_po_group',normalize=True) ##비율
## 전체 장르 확인
df_merged.groupby(['genre','exit_po_group']).count() ##인원수
#읽고 나간 곳은 거의 비슷. 4구간을 같은 비율로 해서 그런 것 같음.
#나누는 구간의 차이를 두어야 할 것 같아보임.
Python
복사
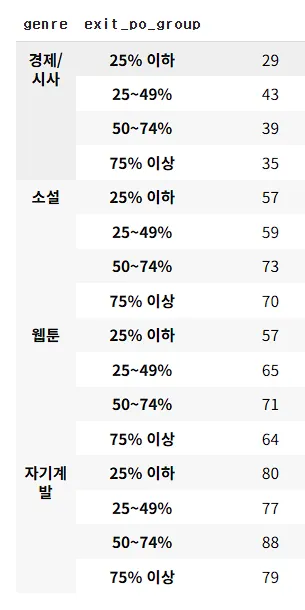
이탈한 대상 1000명 중에 경제/시사 비율이 가장 낮다.
(경제/시사를 읽는 사람들의 비율이 낮을 수 있다)
경제/시사는 높은 충성도를 가졌을 수 있다.
경제/시사 장르 강화하여 충성도 확립할 수 있다.
경제/시사를 읽는 고객들은 광고 타겟으로 적합할 수 있다.
*25% 이하인 사람들이 미리보기 보고왔는지
연령대가 높은 사람들은 검색 유입 비중이 많을 것이다. 승인님
df_merged['age'] = 2023 - df_merged['birthday_filled'].dt.year+1
df_merged['age_group'] = pd.cut(df_merged['age'],
bins=[0,9,19,29,39,49,59,130],
labels=['0대','10대', '20대', '30대', '40대', '50대', '60대 이상'],
right = True)
## 연령대 높음의 기준을 50대 이상으로 설정
#50대 이상 유입채널 비율
df_merged[df_merged['age']>= 50].groupby('entry_channel').count()
###같
df_merged[(df_merged['age_group']=='50대') | (df_merged['age_group']=='60대 이상')].groupby('entry_channel').count()
Python
복사
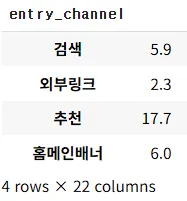
연령대가 높은 사람들은 추천으로 유입된 인원의 이탈이 가장 많다.
연령대가 높은 사람들은 외부링크로 유입된 인원의 이탈이 가장 적다.
*기준을 잡는 것 : 90% 이상은 완독했다고
무료 체험이면 이탈률이 높을 것이다. 수민님
가설 오류
•
이탈률의 정의
이탈률은 (이탈한 사용자 수/전체 사용자 수)로 구할 수 있다. 현재 우리가 갖고 있는 데이터는 이탈한 사람들로만 이루어진 데이터이기에 이탈률을 구할 수 없다.
따라서 성별 별 구독 유형 별 이탈자 수 분포를 구하는 것을 목표로 진행했다.
따라서 성별 별 구독 유형 별 이탈자 수 분포를 구하는 것을 목표로 진행했다. # 성별 별 / 구독 유형 별로 이탈률 구하기
gender_sub = pd.crosstab(
df['subscription_plan'], # 행 인덱스로 사용할 열 지정
df['user_demographics_gender'], # 열 인덱스로 사용할 열 지정
normalize=True, # 정규화 (전체 기준으로 비율 계산)
margins=True, # 총계 포함 여부
margins_name='Total' # 총계 이름 지정
)
print(gender_sub)
>>>
user_demographics_gender female male Total
subscription_plan
free_trial 0.173 0.204 0.377
monthly 0.167 0.138 0.305
pay_per_book 0.168 0.150 0.318
Total 0.508 0.492 1.000
Python
복사
•
분석결과
◦
성별과 관계 없이 free_trial 유형의 이탈 비중이 크다.
◦
성별과 관계 없이 monthly 유형의 이탈 비중이 작다.
•
인사이트
◦
사용자의 몰입도는 구독 유형에 따라 차이가 있다.
무료 체험 사용자는 책을 가볍게 탐색하는 경향이 있고, 콘텐츠에 대한 몰입도나 기대치가 낮을 수 있다. 월간 구독자는 금전적 지불을 했기 때문에 책을 끝까지 읽으려는 의지나 목적의식이 더 강할 수 있다.
◦
성별과 관계 없이 free_trial 유형의 이탈 비중이 크다.
◦
성별과 관계 없이 monthly 유형의 이탈 비중이 작다.
eReader를 이용하는 여성중에는 mz 세대가 많을 것이다. 수민님
•
MZ 세대의 정의 : 1980 ~ 2012년 출생자
# mz 세대 구분하기
birth_year = df['birthday_filled'].dt.year # 출생 년도 구하기
def mz_gen(year): # mz 세대를 구분하는 함수 정의
if 1980 <= year <=2012: # 조건 : 1980년대 ~ 2012년대
return True
else:
return False
df['is_mz'] = birth_year.apply(mz_gen) # 새로운 컬럼 is_mz를 만들어 mz 여부 확인하기
# eReader 사용자 중 여성 mz 세대 비율 구하기
ereader_df = df[df['device_type'] == 'eReader']
total_users = len(ereader_df)
female_ratio = (ereader_df['user_demographics_gender'] == 'female').mean()
mz_ratio = ereader_df['is_mz'].mean()
female_mz_ratio = ereader_df[(ereader_df['user_demographics_gender'] == 'female') & (ereader_df['is mz'])].shape[0] / total_users
female_df = ereader_df[ereader_df['user_demographics_gender'] == 'female']
female_mz_only_ratio = female_df['is_mz'].mean()
result = pd.DataFrame({
'비율(%)': [female_ratio * 100, mz_ratio * 100, female_mz_ratio * 100, female_mz_only_ratio * 100]
}, index=[
'eReader 사용자 중 여성 비율',
'eReader 사용자 중 MZ 세대 비율',
'eReader 전체 사용자 중 여성 MZ 세대 비율',
'eReader 여성 사용자 중 MZ 세대 비율'
])
print(result)
print(result)
>>>
비율(%)
eReader 사용자 중 여성 비율 52.054795
eReader 사용자 중 MZ 세대 비율 54.794521
eReader 전체 사용자 중 여성 MZ 세대 비율 25.570776
eReader 여성 사용자 중 MZ 세대 비율 49.122807
Python
복사
•
분석결과
◦
eReader 사용자 중 여성 mz 세대의 비율은 절반이다.
•
인사이트
◦
mz 세대라고 eReader를 많이 사용하는 것은 아님
검색으로 유입된 사람들은 이탈률이 낮을 것이다. 수민님
가설 오류
•
이탈률의 정의
이탈률은 (이탈한 사용자 수/전체 사용자 수)로 구할 수 있다. 현재 우리가 갖고 있는 데이터는 이탈한 사람들로만 이루어진 데이터이기에 이탈률을 구할 수 없다.
따라서 유입 채널 별 이탈자 수 분포를 구하는 것을 목표로 진행했다.
따라서 유입 채널 별 이탈자 수 분포를 구하는 것을 목표로 진행했다.df['entry_channel'].value_counts(normalize=True)
>>>
entry_channel
추천 0.534
홈메인배너 0.210
검색 0.195
외부링크 0.061
Python
복사
•
분석 결과
◦
검색을 통해 유입된 사람의 비중은 비교적 낮다.
◦
추천을 통해 유입된 사람의 비중은 비교적 높다.
•
인사이트
◦
검색 유입자는 충성도 또는 완독 가능성이 높은 고객군으로 이탈 확률이 낮아질 수 있다.
◦
추천 시스템이 사용자의 선호를 파악하지 못해 이탈하는 것 같다.
◦
검색을 통해 유입된 사람의 비중은 비교적 낮다.
◦
추천을 통해 유입된 사람의 비중은 비교적 높다.
추천 시스템이 사용자의 선호를 파악하지 못해 이탈하는 것 같다.
추천 시스템이 사용자의 선호를 파악하지 못해 이탈하는 것 같다.•
추가적인 데이터 분석 : 사람들이 이탈하는 가장 큰 이유는 무엇일까?
df['dropout_reason_detail_filled'].value_counts(normalize=True)
>>>
dropout_reason_detail_filled
추천 실패 0.325
UX 불편 0.300
지루함 0.130
너무 김 0.130
급한일 0.065
기술 이슈 0.050
Python
복사
•
성별 별 이탈 상세 이유 : 여성
female = df[df['user_demographics_gender'] == 'female']
print(female['dropout_reason_detail_filled'].value_counts(normalize=True))
>>>
dropout_reason_detail_filled
추천 실패 0.318898
UX 불편 0.291339
너무 김 0.139764
지루함 0.137795
급한일 0.066929
기술 이슈 0.045276
Python
복사
•
성별 별 이탈 상세 이유 : 남성
male = df[df['user_demographics_gender'] == 'male']
print(male['dropout_reason_detail_filled'].value_counts(normalize=True))
>>>
dropout_reason_detail_filled
추천 실패 0.331301
UX 불편 0.308943
지루함 0.121951
너무 김 0.119919
급한일 0.063008
기술 이슈 0.054878
Python
복사
•
인사이트
◦
여성과 남성 모두 추천 실패가 가장 큰 이탈 사유였다.
◦
두 번째 이탈 사유는 UX 불편을 생각할 수 있다.
이탈 위치가 높을수록 이탈률이 줄어들 것 같다. 준영님
이탈 위치에 따라서는 이탈한 유저에 대한 이탈정도가 같다고 볼 수 있다
위에서 이미 이탈률에 대한 정의를 알려준 바가 있으며 현 데이터는 모두 이탈 고객에 대한 데이터이기에 정확한 이탈률은 구할 수 없다.
하지만 이탈 위치 즉, 독서율이 높은 고객들이 가장 최근까지 이용을 했을 수 있다고 가설을 해석해볼 수 있다.
filtered_df1 = df_merged[df_merged['exit_position_numeric'] >= 50]
filtered_df2 = df_merged[df_merged['exit_position_numeric'] < 50]
specific_date = datetime(2023, 12, 31)
last_access1 = round((specific_date - filtered_df1['last_access_timestamp_filled']).dt.days / 30, 2)
last_access2 = round((specific_date - filtered_df2['last_access_timestamp_filled']).dt.days / 30, 2)
print(last_access1.mean())
print(last_access2.mean())
5.9
6.0
Python
복사
두 그룹 모두 6개월로 비슷하다고 볼 수 있다.
월 구독을 한 사람들의 최종 접속일이 가장 최근일 것이다. 준영님
최종 접속일이 가장 최근인 구독권은 무료 체험자였다. 단권으로 빌리는 고객들은 이용을 덜 한다.
grouped_df = df_merged.groupby('subscription_plan')[['last_access_timestamp_filled']].max()
print(grouped_df)
last_access_timestamp_filled
subscription_plan
free_trial 2023-12-31 22:00:48
monthly 2023-12-31 13:15:06
pay_per_book 2023-12-30 13:55:11
Python
복사
결론적으로는 무료 체험자가 가장 최근에 접속을 했지만 그렇다면 세 구독 종류 중에서 평균적으로 가장 이탈기간이 긴 유형은 어디일까?
# 인원 수
filtered_df = df_merged[df_merged['subscription_plan'] == 'pay_per_book']
specific_date = datetime(2023, 12, 31)
filtered_df['dropout_date'] = round(((specific_date - filtered_df['last_access_timestamp_filled']).dt.days) / 30, 2).count()
print(filtered_df['dropout_date'])
# 평균
filtered_df = df_merged[df_merged['subscription_plan'] == 'pay_per_book']
specific_date = datetime(2023, 12, 31)
filtered_df['dropout_date'] = round(((specific_date - filtered_df['last_access_timestamp_filled']).dt.days) / 30, 2).mean()
print(filtered_df['dropout_date'])
#결론
free_trial 377명 5.692467개월
monthly 305명 5.955016개월
pay_per_book 318명 6.298365개월
Python
복사
전체 이용자들 중에서 평균적으로 가장 오랜 기간동안 이탈을 한 유저는 pay_per_book으로 평균 6.2개월임을 알 수 있다.
1020 사용자 중에는 pay per book 비중이 높아서 이탈률이 높을 것이다.
+ pay per book 구독 유형을 가진 사람들은 이탈률이 50% 미만일 것이고 최근 접속일이 가장 오래됐을 것이다. 준영님
pay_per_book을 이용한 10~20대 여성 고객들 중 50% 미만으로 읽으신 분이 평균적으로 이탈기간이 더 높음을 알 수 있었다.
#정확한 나이대를 알기 위해서는 특정 기준일에서 데이터 birthday 값을 빼야지만 알 수 있었다.
current_year = datetime.now().year
df_merged['age'] = current_year - pd.to_datetime(df_merged['birthday_filled']).dt.year
# 조건 필터링: 여성 유저 & 10~20대 & pay_per_book 구독
filtered_df = df_merged[(df_merged['user_demographics_gender'] == 'female') &
(df_merged['age'].between(10, 29)) &
(df_merged['subscription_plan'] == 'pay_per_book') &
(df_merged['exit_position_numeric'] >= 50)]
-
# 여성, 10~20, pay_per_book, 정독률 50 미만일때 21명 35 (56) // 여성, 10~20, pay_per_book 56명 52[m], 55[ft], 56 total : (163)// 여성, 10~19 81명 20~29 82, 30~39 90, 40~49 79, 50~ 59 84, 60~69 81, 100~120 11
# 여성, 10~20, pay_per_book, 정독률 50 미만인 21명의 이탈 기간
# [6.9, 0.3, 6.5, 8.43, 1.63, 5.97, 5.47, 9.47, 11.27, 1.47, 0.17, 1.6, 9.7, 6.57, 5.7, 11.77, 7.17, 4.53, 8.97, 10.23, 1.8]
# 여성, 10~20, pay_per_book, 정독률 50 이상인 35명의 이탈 기간
# [5.63, 2.07, 12.0, 0.93, 5.87, 3.23, 8.47, 10.9, 5.97, 3.93, 11.6, 12.0, 0.13, 10.97, 5.57, 8.83, 6.07, 3.8, 4.53, 6.8, 1.33, 3.87, 2.43, 3.27, 7.23, 3.13, 10.17, 10.37, 0.3, 0.17, 9.83, 6.93, 5.7, 2.93, 1.3]
print(filtered_df['dropout_date'].tolist())
Python
복사
pay_per_book을 이용한 10~20대 여성 고객들 중 50% 미만으로 읽으신 분이 평균적으로 이탈률이 더 높음을 알 수 있었다.
Gruop1 독서율 50% 미만인 10~20대 여성 5.98개월
독서율 50% 미만인 10~20대 여성 5.98개월Gruop2 독서율 50% 이상인 10~20대 여성 5.66개월
독서율 50% 이상인 10~20대 여성 5.66개월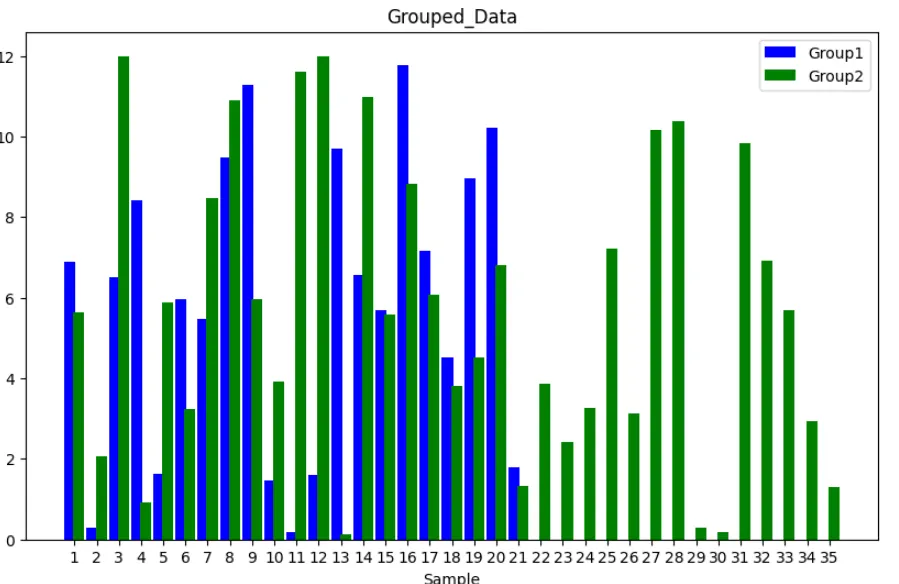
추천을 받지 않고 소설을 본 사람들의 이탈률은 낮을 것이다. 시현님
[이탈률 기준 설정] 0-40 : 초반 | 40-60 : 중간 | 60-90 : 후반
→ 60 미만 이탈률 높다고 기준 (low = 이탈률 | high = 이탈률 )
| high = 이탈률 )[성별 기준] 여성 기준 (페르소나 설정)
# 여성만 추출
df_female = df.loc[df['user_demographics_gender']=='female']
# 추천을 받지 않고, 소설 장르이며, 중단 이탈이 60% 미만인 사람
df_female['is_exit_total_rate'] = (df_female['entry_channel'] != '추천') & \
(df_female['genre'] == '소설') & \
(df_female['exit_position_numeric'] < 60)
df_female['is_exit_total_rate']
# 장르와 유입경로별 이탈률
df_channel_novel_exit_rate = (df_female.groupby(['genre', 'entry_channel'])['is_exit_total_rate'] \
.value_counts(normalize=True) \
.unstack() \
.rename(columns={False: 'low', True: 'high'}))
df_channel_novel_exit_rate.round(2)
# 소설이 아닌 값은 NaN값이 나오므로 drop
df_channel_novel_exit_rate.dropna().round(2)
Python
복사
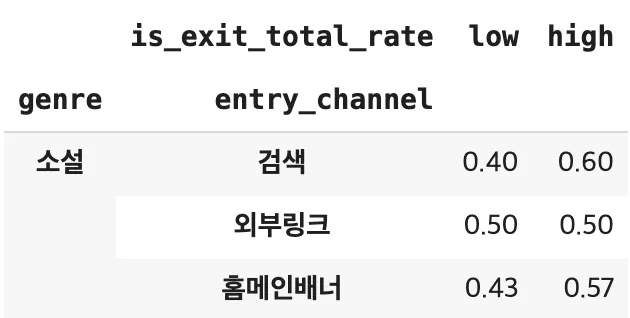
[Insight 도출]
가설과 달리 외부링크가 50:50인 것을 제외하면
추천을 받지 않고 소설을 선택해 읽은 사람들의 이탈률은 상대적으로 높은 편이다.
웹툰을 읽는 사람들의 이탈률은 더 낮을 것이다. 시현님
[이탈률 기준 설정] 0-40 : 초반 | 40-60 : 중간 | 60-90 : 후반
→ 60 미만 이탈률 높다고 기준 (low = 이탈률 | high = 이탈률 )
| high = 이탈률 )# 0-40 초반 | 40-60 중간 | 60-90 후반 60 이하 이탈률 높다고 기준
df['is_exit_rate'] = df['exit_position_numeric'] < 60
# 전체 장르별 이탈률
df_genre_exit_rate
= df.groupby('genre')['is_exit_rate'] \
.value_counts(normalize=True) \
.unstack() \
.rename(columns={False: 'low', True: 'high'})
df_genre_exit_rate.round(2)
Python
복사
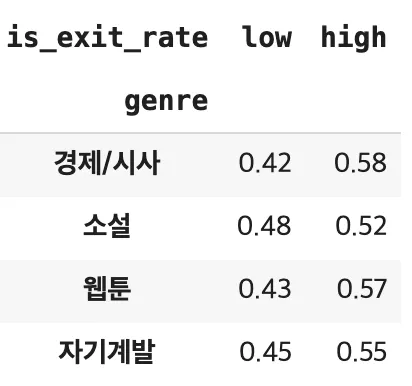
# 여성만 추출
df_female = df.loc[df['user_demographics_gender']=='female']
# 60 이하 기준
df_female['is_exit_rate']
= df_female['exit_position_numeric'] < 60
# 여성 장르별 이탈률
df_genre_exit_rate
= df_female.groupby('genre')['is_exit_rate']
.value_counts(normalize=True) \
.unstack() \
.rename(columns={False: 'low', True: 'high'})
df_genre_exit_rate.round(2)
Python
복사
[Insight]
남여 성별 구분 없이 데이터 분석 시 경제/시사 다음으로 이탈률이 높다.
여성만 구했을 경우 웹툰 이탈률이 가장 낮다.
(60% 이상 읽은 비율이 44%로 가장 높다.)
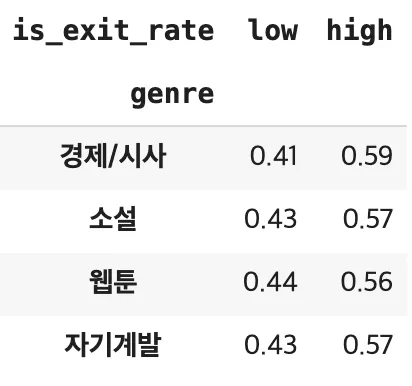
홈 메인 베너 / 자기계발 + 소설을 본 사람들의 이탈률이 적을 것이다. 시현님
[이탈률 기준 설정] 0-40 : 초반 | 40-60 : 중간 | 60-90 : 후반
→ 60 미만 이탈률 높다고 기준 (low = 이탈률 | high = 이탈률 )
| high = 이탈률 )# 조건 설정 : 유입경로가 홈메인배너, 중단 위치가 60% 미만
df['is_exit_total_rate'] = (df['entry_channel'] == '홈메인배너') & \
(df['exit_position_numeric'] < 60)
# 이탈률
df_channel_genre_exit_rate = (df.groupby(['genre', 'entry_channel'])['is_exit_total_rate']
.value_counts(normalize=True)
.unstack()
.rename(columns={False: 'low', True: 'high'}))
df_channel_genre_exit_rate.round(2)
# NaN 값 drop
df_channel_genre_exit_rate.dropna().round(2)
Python
복사
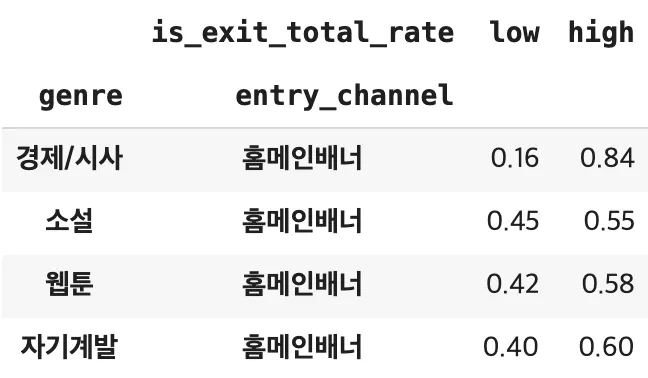
소설, 자기계발 이탈률이 경제/시사와 비교하면 적은 편이다.
테마 모드가 customize / dark mode인 사용자들은 이탈률이 더 낮을 것이다. 문수님
•
사용자 경험(UX)에 관해 개인화 및 시각적 편안함이 사용자 유지에 긍정적 영향을 줄 것이다. 따라서 "theme_mode가 'customize' 또는 'dark'인 사용자들은 'light' 사용자보다 더 늦은 시점에서 독서를 중단할 것이다. exit_position_numeric 값이 더 높을 것.
# 'dark'과 'customize'를 하나의 그룹 'dark_or_custom'으로 묶고, 나머지('light')는 그대로 사용
df_merged['theme_group'] = df_merged['theme_mode'].apply(lambda x: 'dark_or_custom' if x in ['dark', 'custom'] else 'light')
print(f"# 그룹핑 된 결과 확인 : {df_merged['theme_group']}")
# 각 테마 그룹에 대해 이탈 시점(exit_position_numeric)의 통계치를 계산 : mean: 평균 이탈 시점이 높을수록 콘텐츠를 더 오래 읽음
summary = df_merged.groupby('theme_group')['exit_position_numeric'].agg(['count', 'mean', 'std', 'median']).reset_index()
print(f"\n테마 그룹별 이탈 시점 요약 : {summary}")
"""
결과 해석 :
테마 그룹별 이탈 시점 요약 : theme_group count mean std median
0 dark_or_custom 607 50.016474 28.843719 50.0
1 light 393 52.867684 29.529435 56.0
평균 :
dark_or_custom: 50.02% 에서 이탈
light: 52.87% 에서 이탈
→ light 사용자들이 조금 더 오래 읽고 이탈하는 경향
중앙값 :
dark_or_custom: 50.0
light: 56.0
→ dark_or_custom 사용자는 50.0% 지점에서 절반이 이탈한 반면, ligt 사용자는 56.0% 지점에서 더 늦게 절반이 이탈함
표준편차 :
dark_or_custom: 28.8
light: 29.5
→ 표준편차가 28~29면 상당히 다양한 시점에서 이탈하고 있다고 해석. 전체가 100이 최대니까 30이라는 분산은 전체 범위의 30%에 해당하는 수준
인사이트 요약 :
light 테마 사용자는 평균 52.9% 지점에서 이탈하며, dark/customize 테마 사용자(50.0%)보다 더 늦게 이탈하는 경향을 보인다.
light 테마 사용자가 콘텐츠를 더 오래 소비하고, 반대로 dark/custom 사용자들은 빠르게 판단하고 빠지는 유형일 수 있다.
"""
Plain Text
복사
모바일 사용/ 장르가 웹툰이 아닌 비웹툰 장르 / 중단 사유가 ‘UX 불편’에 해당하는 사람들의 이탈률이 높을 것이다. 문수님
•
모바일 사용자가 웹툰이 아닌 비웹툰 장르를 이용할 때, 화면 크기 제한으로 인해 UX(사용자 경험) 불편을 겪을 가능성이 높아 이탈률이 높을 것이다.
# 1. 1차 필터링 : 모바일 사용자 필터링
df_mobile = df_merged[df_merged['device_type'] == 'mobile']
# 2. 2차 필터링 : 모바일 사용자 중 웹툰 여부, 컬럼 추가 :genre가 ‘웹툰’인지 여부를 True/False로 담은 새로운 컬럼 is_webtoon
df_mobile['is_webtoon'] = df_mobile['genre'] == '웹툰'
# 3. 3차 필터링 : UX 불편으로 중단한 사용자 필터링 : 모바일 x 여러 장르 x ['is_webtoon] x UX 불편 -> 새로운 DataFrame 생성(df_ux_issue)
df_ux_issue = df_mobile[df_mobile['dropout_reason_category'] == 'UX 불편']
# 4. 웹툰 vs 비웹툰 독서 중단 위치 평균 계산 : 모바일 x UX 불편 x ['is_webtoon] : Ture(웹툰)/False(비웹툰) x ['exit_position_numeric']
exit_by_webtoon = df_ux_issue.groupby('is_webtoon')['exit_position_numeric'].mean().reset_index()
print(f"모바일 사용자 중 UX 불편을 겪는 사용자의 비웹툰/웹툰 별 독서 중단 위치 평균:")
print(exit_by_webtoon)
"""
결과 해석 :
is_webtoon exit_position_numeric
0 False 53.767857
1 True 46.469388
인사이트 요약 :
모바일에서 UX 불편을 겪은 사용자 중 비웹툰 장르가 웹툰보다 평균 독서 중단 위치가 더 높다.
비웹툰 장르 사용자들이 UX 불편에도 불구하고 웹툰 사용자보다 중단 시점이 늦다. 더 오래 읽었다.
따라서 "비웹툰에서 UX 불편으로 더 빨리 이탈할 것이다”라는 가설과는 정반대 결과를 얻음.
"""
Plain Text
복사
GOAL
•
2~3구간에 있는 사용자의 독서 중단 범위를 4구간(완독 가능성이 가장 높거나 완독한) 이상으로 높이기
•
2~3구간에 있는 사용자의 유료 결제 구독 유형으로 전환하기
EX. monthly, pay per book 구독 유형의 사람들이 독서 중단 범위가 더 높았다는 가설이 검증되면 사용…!
INSIGHT
•
NEXT LEVEL
이탈률에 대한 정의 - 이탈 지점에 대한 범위 (독서 중단 범위)
•
WHY? 2~3구간? : 2~3구간을 포함한 타겟군을 50% 초과 확장(4구간 : 완독 가능성이 가장 높은 구간 or 1구간 : 완독 가능성이 가장 낮은 구간 포함)하지 않고도 완독 가능성이 어느 정도 있는 전체 48%에 해당하는 사람들을 집중타겟
1구간 | 15% 미만 | 140 | |
2구간 | 15~40% | 239 | |
3구간 | 41~65% | 245 | |
4구간 | 66~90% | 278 | |
완독 | 90% 초과 | 98 |
# 구간별 유저 수
df['exit_po_group'] = pd.cut(
df['exit_position_numeric'],
bins=[-1, 14, 40, 65, 90, 100],
labels=['15% 미만', '15~40%', '41~65%', '66~90%', '90% 초과'],
right=True
)
>>>
target_group = df[(df['exit_po_group'] == '15~40%') | (df['exit_po_group'] == '41~65%')]
Python
복사
특정 유저의 특성 / 행동 데이터 파악하기
•
나이대 → 2030 선택
# 나이 구하기
birth = target_group['birthday_filled'].dt.year # 출생년도에서 년 정보만 추출
current_year = 2023 # 현재 년도 설정
year_age = current_year - birth + 1 # 나이 구하기 (연나이 기준)
target_group['age'] = year_age # 1000 non-null / int32 'age' 컬럼 생성
def age_categorize(age): # 나이대 범주화
age = (age // 10) * 10
return age
age_category = target_group.age.apply(age_categorize) # apply()로 age컬럼 전 데이터에 적용
target_group['age_category'] = age_category # 새로운 컬럼'age_category' 생성
>>>
age_category count
50 86
30 82
40 82
10 79
20 75
60 61
100 11
0 8
비율 ver
50 0.177686
30 0.169421
40 0.169421
10 0.163223
20 0.154959
60 0.126033
100 0.022727
0 0.016529
Python
복사
•
성별 분포 → 여성 남성 모두 포함
target_group_age = target_group[(target_group['age_category'] == 20) | (target_group['age_category'] == 30) ]
target_group_age['user_demographics_gender'].value_counts()
>>>
male 80
female 77
Python
복사
target group | male 80
female 77 | male 0.51
female 0.49 |
group 1
2-3구간 O, 연령대 2030 X : | male 163
female 164 | male 0.498
female 0.501 |
group 2
2-3구간 X, 연령대 2030 O : | male 91
female 91 | male 0.5
female 0.5 |
group 3
2-3구간 X, 연령대 2030 X : | male 158
female 176 | male 0.47
female 0.53 |
•
이탈 비중이 많았던 장르
target_group_age['genre'].value_counts()
>>>
자기계발 48
웹툰 45
소설 38
경제/시사 26
Python
복사
target group | 자기계발 48
웹툰 45
소설 38
경제/시사 26 | 자기계발 0.305732
웹툰 0.286624
소설 0.242038
경제/시사 0.165605 |
group 1
2-3구간 O, 연령대 2030 X : | 자기계발 110
웹툰 88
소설 75
경제/시사 54 | 자기계발 0.336391
웹툰 0.269113
소설 0.229358
경제/시사 0.165138 |
group 2
2-3구간 X, 연령대 2030 O : | 소설 55
자기계발 54
웹툰 49
경제/시사 24 | 소설 0.302198
자기계발 0.296703
웹툰 0.269231
경제/시사 0.131868 |
group 3
2-3구간 X, 연령대 2030 X : | 자기계발 117
소설 93
웹툰 80
경제/시사 44 | 자기계발 0.350299
소설 0.278443
웹툰 0.239521
경제/시사 0.131737 |
•
이탈 사유
target_group_age['dropout_reason_detail_filled'].value_counts()
>>>
추천 실패 58
UX 불편 48
지루함 19
너무 김 15
기술 이슈 9
급한일 8
Python
복사
target group | 추천 실패 58
UX 불편 48
지루함 19
너무 김 15
기술 이슈 9
급한일 8 | 추천 실패 0.369427
UX 불편 0.305732
지루함 0.121019
너무 김 0.095541
급한일 0.057325
기술 이슈 0.050955 |
group 1 | 추천 실패 164
UX 불편 140
지루함 65
너무 김 62
급한일 31
기술 이슈 22 | 추천 실패 0.338843
UX 불편 0.289256
지루함 0.134298
너무 김 0.128099
급한일 0.064050
기술 이슈 0.045455 |
group 2 | 추천 실패 61
UX 불편 49
너무 김 25
지루함 23
기술 이슈 13
급한일 11 | 추천 실패 0.335165
UX 불편 0.269231
너무 김 0.137363
지루함 0.126374
기술 이슈 0.071429
급한일 0.060440 |
group 3 | UX 불편 111
추천 실패 100
너무 김 43
지루함 42
급한일 23
기술 이슈 15 | UX 불편 0.332335
추천 실패 0.299401
너무 김 0.128743
지루함 0.125749
급한일 0.068862
기술 이슈 0.044910 |
•
유입 경로
target_group_age['entry_channel'].value_counts()
entry_channel
추천 83
검색 34
홈메인배너 34
외부링크 6
Python
복사
target group | 추천 83
검색 34
홈메인배너 34
외부링크 6 | 추천 0.528662
검색 0.216561
홈메인배너 0.216561
외부링크 0.038217 |
group 1 | 추천 257
홈메인배너 109
검색 94
외부링크 24 | 추천 0.530992
홈메인배너 0.225207
검색 0.194215
외부링크 0.049587 |
group 2 | 추천 104
홈메인배너 39
검색 26
외부링크 13 | 추천 0.571429
홈메인배너 0.214286
검색 0.142857
외부링크 0.071429 |
group 3 | 추천 173
검색 75
홈메인배너 62
외부링크 24 | 추천 0.517964
검색 0.224551
홈메인배너 0.185629
외부링크 0.071856 |
•
추천 콘텐츠 클릭 여부 차이 없음
target_group_age['recommendation_clicked'].value_counts()
>>>
recommendation_clicked
True 107
False 50
target group | True 107
False 50 | True 0.681529
False 0.318471 |
group 1 | True 319
False 165 | True 0.659091
False 0.340909 |
group 2 | True 125
False 57 | True 0.686813
False 0.313187 |
group 3 | True 219
False 115 | True 0.655689
False 0.344311 |
2.
문제 상황에서 어떤 사유로 이탈했는지 분석
리디의 서재가 직면한 주요 배경•
많은 유저가 책을 열람하지만, 초반 몇 페이지만 읽고 중단하는 경우가 빈번하게 발생합니다.
•
같은 책이라도 유저마다 이탈 행동은 다릅니다.
◦
지루해서, 너무 길어서, 추천이 맞지 않아서 등
•
우리는 이 행동의 차이를 분석하고, 데이터를 기반으로 ‘왜 읽지 않았는가’를 해석할 수 있어야 합니다.
3.
범위 나눴을 때 구간 내에 있는 유저 설정 (범위 좁히기) → 해당 유저의 이탈 위치 높이기 전략
4.
해당 유저의 특성, 행동, 문제(어려움) 분석 Ex. 기기 유형, 선호 장르, 구독 유형 등
5.
가설 설정
6.
완독률을 높일 수 있는 아이디어 제시하기
7.
아이디어를 실험해볼 수 있는 방법 설계해보기 + 기대효과 예상하기

[오늘 할 일]
•
가설 도출
•
공통적인 세부적인 사항 결정
수빈 튜터님 피드백•
타깃을 2030으로 좁혔는데 그 외의의 데이터는 보지 않은 것 같다는 느낌을 받음
•
타깃 유저를 분석한 결과가 그 집단의 특징일 수 있지만 그 이외의 타깃에게 동일하게 나타나는 현상일 수 있음 → 좋은 데이터 결과로 볼 수 없음
•
타깃 외의 데이터 보는 것 추천 : 2030에만 나타나는 특징인지 비교분석 필요
•
타깃의 실제 문제가 무엇인지 분석 → 해결책 모색
•
분석 여러 갈래로 해보기 → 시각화
◦
구간별 / 나이별 분석 과정을 거쳐서 2,3 구간 & 2030 세대인 사람들과의 차별점 찾기
▪
구간 2-3구간
▪
연령대 2030
•
2-3구간 O, 연령대 2030 X :
•
2-3구간 X, 연령대 2030 O :
•
2-3구간 X, 연령대 2030 X :
[6/18 (수)]
•
데이터 분석 결과 토대로 아이디어
수요일 7시 팀 회의
