
 구독 플랜별 이탈 시점에서 유의미한 차이를 보일 것이다.
구독 플랜별 이탈 시점에서 유의미한 차이를 보일 것이다.
→ 구독 플랜이 유료인 유저가 더 적게 이탈할것이다.
퍼포먼스 마케터 관점의 핵심 : 구매한 유저가 더 오래 쓰고 덜 이탈했다는걸 객관적인 수치로 제대로 보여야함.Task
팀원들과 논의해야할 부분
분석에 필요한 칼럼들•
subscription_plan
•
exit_position_numeric
•
dropout_reason_category
•
dropout_reason_detail
•
last_access_timestamp
필요한 데이터 전처리•
구독 플랜 유료 VS 무료 비교
•
이탈 여부 : 이탈 유저만 구분해서 이탈률, 행동 패턴 분석 가능하게 만들기
◦
마지막 접속 시간을 datetime으로 변환해 → 접속 종료 시점 파악하기
•
exit_position_numeric 칼럼 통해서 “평균 이탈 위치 분석”
실행 및 진행 사항 정리
1 구독 플랜 유료 vs 무료 비교 ⇒ free_trial을 쓰는 유저가 가장 많음2 이탈 여부 : 이탈 유저만 구분해서 이탈률, 행동 패턴 분석 가능하게 만들기3 exit_position_numeric 칼럼 통해서 “평균 이탈 위치 분석”바탕 - 분석 내용
결과
구독 플랜 별 평균 이탈시점, 이탈률, 마지막 접속 시간
수정 전
수정 후
1.
비율 기준
# 1. 평균 이탈 위치
exit_mean = final_merge.groupby('subscription_plan')['exit_position_numeric'].mean()
# 2. 이탈률 계산
dropout_rate = final_merge.groupby('subscription_plan')['이탈여부확인'].apply(
lambda x: (x == '이탈').mean())
# 3. 활동 시간대(work_last_access_time) 분포 (비율)
work_time_dist = final_merge.groupby(['subscription_plan', 'work_last_access_time']).size().unstack(fill_value=0)
work_time_dist = work_time_dist.div(work_time_dist.sum(axis=1), axis=0) # 비율로 정규화
# 4. 이탈 사유(category) 분포 (비율)
dropout_cat_dist = final_merge.groupby(['subscription_plan', 'dropout_reason_category']).size().unstack(fill_value=0)
dropout_cat_dist = dropout_cat_dist.div(dropout_cat_dist.sum(axis=1), axis=0) # 비율로 정규화
# 5. 하나로 합치기
summary_df = pd.DataFrame({
'평균 이탈 위치': exit_mean,
'이탈률': dropout_rate
})
# 6. 활동 시간대와 이탈 사유 비율 통합
summary_df = summary_df.join(work_time_dist, how='left')
summary_df = summary_df.join(dropout_cat_dist, how='left')
# 보기 좋게 정렬
summary_df.reset_index(inplace=True)
Python
복사

2.
개수 기준
# 1. 평균 이탈 위치
exit_mean = final_merge.groupby('subscription_plan')['exit_position_numeric'].mean()
# 2. 이탈률 계산 (요청한 방식 그대로)
dropout_rate = final_merge.groupby('subscription_plan')['이탈여부확인'].apply(
lambda x: (x == '이탈').mean()
)
# 3. 활동 시간대(work_last_access_time)별 count
work_time_count = final_merge.groupby(['subscription_plan', 'work_last_access_time']).size().unstack(fill_value=0)
# 4. 이탈 사유(category)별 count
dropout_cat_count = final_merge.groupby(['subscription_plan', 'dropout_reason_category']).size().unstack(fill_value=0)
# 5. 하나로 합치기
summary_df = pd.DataFrame({
'평균 이탈 위치': exit_mean,
'이탈률': dropout_rate
})
summary_df = summary_df.join(work_time_count, how='left')
summary_df = summary_df.join(dropout_cat_count, how='left')
summary_df.reset_index(inplace=True)
# 결과 보기
summary_df
Python
복사

여기서 도출할 수 있는 결론
•
큰 가설에서 나온 세부 내용에 대한 가설은 맞다.
구독 플랜이 유료인 유저 일수록 더 작게 이탈하지만, 이탈률을 봤을때 엄청나게 유의미한 차이가 나오진 않았다.
팀원들 피드백 : 결론은 다 합쳐서 정하는게 좋을것같다고 생각!
튜터님께질문:
•
이렇게 구독플랜을 기준으로 여러개의 값을 한번에 넣어 비교하는게 맞는지도 궁금합니다!
•
제가 도출한 결론은 가설 검증으로 진행한거라 이렇게 결론을 도출하는게 맞는지도 궁금합니다.
### 코멘트
1. "구독플랜을 기준으로 여러개의 값을 한번에 넣어 비교"
=> 매우 적절한 접근
2. "이렇게 결론을 도출하는게 맞는지"
=> 네, 현재 분석 방식은 탐색적 데이터 분석(EDA)을 통한 가설 검증의 기본적인 절차를 충실히 따르고 있습니다.
- 가설 설정: 유료 구독자는 더 적게 이탈할 것이다.
- 데이터 분석: 구독 플랜별로 이탈률, 이탈 위치, 접속 시간, 이탈 이유 등을 수치로 확인.
- 결론 도출: 전체적인 경향은 확인되지만, 유의미한 차이는 크지 않다.
다만 결론(인사이트) 도출 전에 다양한 시각화 작업을 통해 데이터분석을 더 면밀하게 진행하고
인사이트 도출후 보고서 작성히 첨부해야 합니다.
JavaScript
복사
실행 및 진행 사항 정리
1 구독 플랜에 따른 시간대별 이탈 시점 분석 → 저녁에 가장 많은 유저들이 책을 읽다 이탈함
어디서 많이 이탈했는지 ⇒ 자발적으로 이탈한 사람이 가장 많음.
결과
1.
저녁(17:00:01~05:59:59)에 가장 많은 유저들이 책을 읽다 이탈하나, 유료 플랜을 쓰고 있는 유저들이 free_trial에 비해 이탈수가 적은것으로 발견
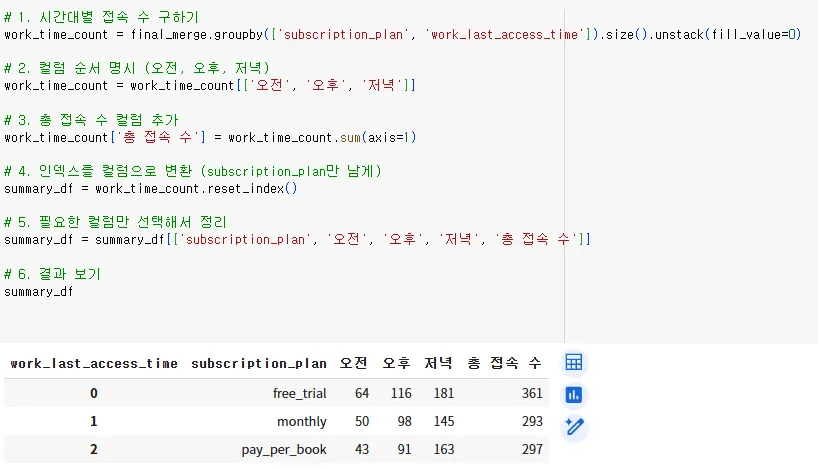
2.
자발적으로 이탈한 사람이 가장 많은데, 모든 구독 플랜의 유저들이 동등하게 추천에 실패했다는 이유로 가장 많은 인원이 이탈
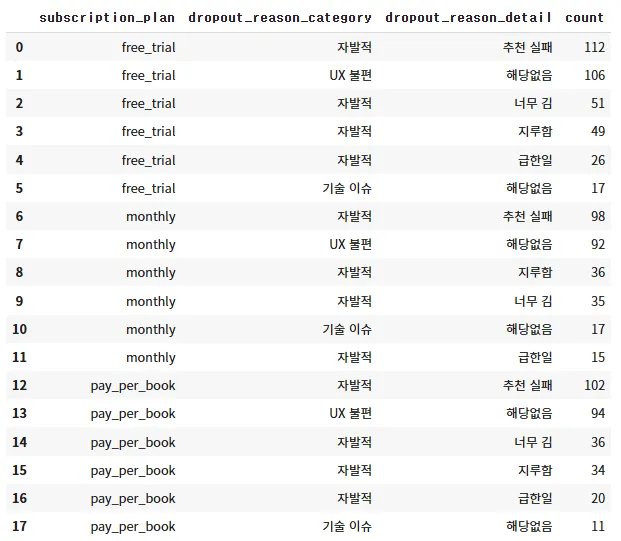

결론 : 구독플랜을 하나하나 나눠보면 유의미한 결과가 크게 나오진 않지만, 무료와 유료를 나눠 계산을 해보면 조금 더 유의미한 결과 도출 가능!
⇒ 유료 플랜을 구독하고 있는 유저가 덜 이탈한다. 가설과 일치.
⇒ 유료와 무료 플랜 비교 : 표가 덜 만들어짐.. ㅜㅜ