


팀원별
지연
세희
민규
승인
수민
전처리 방법
결측치
•
Gender : drop
•
Add-ons Purchased : None
•
Payment Method : Paypal
df['Payment Method'] = df['Payment Method'].replace('PayPal','Paypal')
Python
복사
파생변수 컬럼 생성
•
age_group : 10대 / 20대 / 30대 / 40대 / 50대 / 60대 / 70대 이상
#나이 그룹 파생 변수
bins_age = [0, 10, 20, 30, 40, 50, 60, 70, 80, np.inf]
labels_age = ['low 10s', '10s', '20s', '30s', '40s', '50s', '60s', '70s', '80s +']
df['age_group'] = pd.cut(df['Age'].astype(float), bins=bins_age, labels=labels_age, right=False)
#최저 최하 이상치 있는지 확인
lowest_Age = df['Age'].min()
highest_Age = df['Age'].max()
print(f"연소자: {lowest_Age}세,{(df['Age']==lowest_Age).sum()}명")
print(f"연장자: {highest_Age}세,{(df['Age']==highest_Age).sum()}명")
#연소자: 18세,301명
#연장자: 80세,289명 이상 없음.
Python
복사
•
Total : Total Price + Add-on Total
df['Total'] = df['Total Price'] + df['Add-on Total']
Python
복사
•
Price_group : 4분위수 (Q1,Q2,Q3,Q4)
# 1분위~4분위
labels = ['Q1', 'Q2', 'Q3', 'Q4']
# Total 값을 기준으로 4분위로 나눔
df['Total_group'] = pd.qcut(df['Total'], q=4, labels=labels) #qcut=분위 따라서 나누는 함수
df['Total_group'].value_counts() #확인 결과 각 5000으로 잘 나뉘어짐
Python
복사
•
Retention : True(재구매) / F(신규 고객) <탐색적 데이터 분석 추가 필요, 인터벌도 확인>
repeat_customers = df[df['Order Status'] == 'Completed']['Customer ID'].value_counts()
repeat_customers = repeat_customers[repeat_customers >= 2].index
#구매 횟수별 사용자 특성 비교 필요/한 번 구매 후 취소한 사람 같은 것
df['Retention'] = df['Customer ID'].isin(repeat_customers)
Python
복사
데이터 수정 사항
•
Product Type & SKU 불일치 row → drop
Data = Data[Data['Unit Price'].map(Data['Unit Price'].value_counts()) > 1]
Python
복사
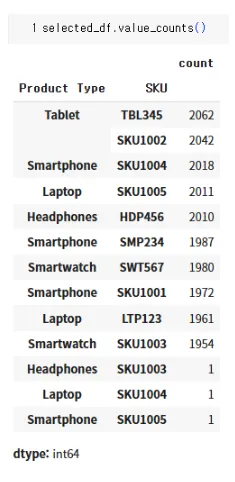
•
Laptop - SKU1004
•
Smartphone = SKU 1004
•
Smartphone - SKU1005
•
Headphones - SKU1003
4개 데이터 DROP
질문
•
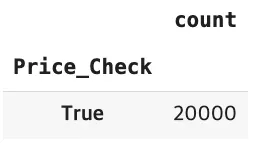
Total Price = Unit Price * Quantity
df['Price_Check'] = round(df['Total Price']) == round((df['Unit Price'] * df['Quantity']))
#round처리해서 우리가 2진수의 문제인지 확인
df['Price_Check'].value_counts()
#True =20000개 나옴. 2진수 문제인 것 확인
Python
복사
•
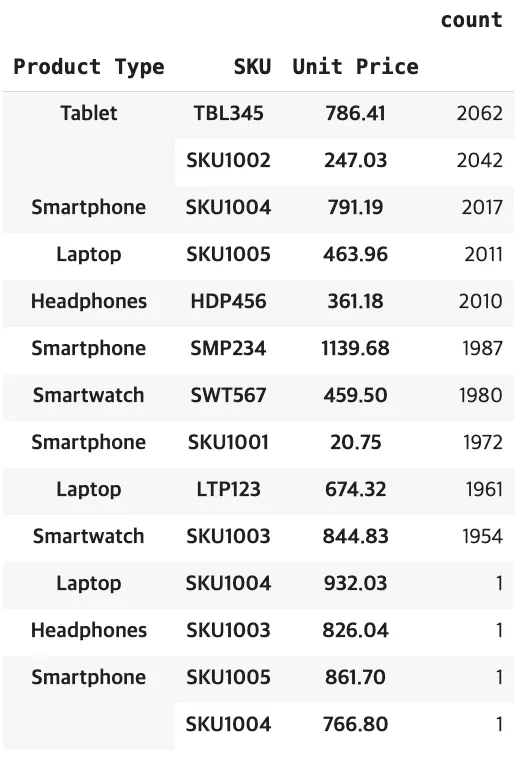
위의 데이터가 오류가 맞는지…? (데이터 수정 사항)
selected_df = df[['Product Type', 'SKU', 'Unit Price']] #스큐가 다른 상품이지는 않을까 확인
selected_df.value_counts()
#실무에서는 직접 담당부서 보통 확인하는데 우리는 최대한 근거를 가지고 대치하고자 해서 틀린 컬럼의 값을 봤음
Python
복사
•
product type과 sku가 동일하지 않은 row가 발생. 이에 unit price를 보고 값을 대치하려 했으나, unit price도 맞지 않을 뿐더러, unit price가 맞지 않는 칼럼 1개 추가 발생. 튜터 피드백은” 보통 담당부서에 가서 데이터 오류를 파악한다” 했으나 현재 담당부서 확인이 불가능한 상태로 drop처리
결과
문길래 튜터님 피드백•
Retention : True(재구매) / F(신규 고객) <탐색적 데이터 분석 추가 필요, 인터벌도 확인>
repeat_customers = df[df['Order Status'] == 'Completed']['Customer ID'].value_counts()
repeat_customers = repeat_customers[repeat_customers >= 2].index
#구매 횟수별로 비교 필요
df['Retention'] = df['Customer ID'].isin(repeat_customers)
Python
복사
•
한 번 구매 고객, 한 번 이상 구매 고객보다 두 번 구매에서 세 번 구매까지 가기가 힘듦 ..
•
두 번 산 사람이 세 번 사게 하는 방법
•
첫 번째 구매했다가 캔슬한 이유 뭘까?
•
첫 번째 구매부터 두 번째 구매한 시점 / 인터벌 확인
구매 여부&날짜 / 취소 여부&날짜
Customer ID | Order Status | Purchase Date | Product type |