
.png&blockId=21b2dc3e-f514-818b-b72b-f9aade6351bf)

Task : 기준을 나눠야 하는 이유.
핵심 목표: 비인기 숙소/수익이 잘 나지 않는 숙소의 수익을 올려 전체적인 수익 증대
⇒ 우리의 목표는 인기도 측정 후, 비인기 숙소의 수익을 올려 전체적인 수익을 증대 해야 함.
하지만, 미운영, 운영, 보류 (신규 OR 잠시 휴식 OR 리모델링 등) 을 나누지 않고, 진행한다면 비인기 숙소와 인기 숙소를 극명하게 판단 할 수 없음.
인기도 - 예약 가능일 수 자체가 0 인 애들이 17000개 임으로 다 날리고 인기도를 측정하는 건. 문제가 생길 수 있음
따라서 먼저. 미운영, 운영, 보류를 기준을 나누고,
운영 중이라고 판단한 숙소들만 가지고 인기와 비인기를 나눠야 함.
⇒ 미 운영 및 보류라고 판단 할 수 있는 아이들은 제거 해야. 목표에 더 가까워질 수 있음.
⇒ 그 이후에는 보류인 아이들의 지역 별 특징( 우리가 얻은 인사이트로 각 지역 별 특징에 따라. 마케팅 전략을 펼치는 것이 더 안전하다고 느낌
즉, 총 리뷰 수가 0 + 라스트 리뷰 NaT, 한 달 평균 리뷰 수 NaN 이면서 예약 가능일 수가 0이 아닌 애들
라스트 리뷰의 null 값 총 10052개
비운영 판단
비운영 조건 요약 (1~5번)
1. 조건 1
•
리뷰가 단 1개도 없는 경우
•
다음 4가지 조건을 모두 만족
◦
총 리뷰 수 = 0
◦
last_review가 없음 (결측값)
◦
한 달 평균 리뷰 수 = NaN
◦
예약 가능 일수 = 0
2. 조건 2
•
2011년에 단 1건의 리뷰만 존재
◦
last_review가 2011년
◦
총 리뷰 수 <= 25
◦
예약 가능 일수 = 0 또는 1
3. 조건 3
•
2012년 리뷰가 6개 이하 & 예약 불가
◦
last_review가 2012년
◦
총 리뷰 수 ≤ 6
◦
예약 가능 일수 = 0
4. 조건 4
•
2013년 리뷰가 24개 이하 & 예약 불가
◦
last_review가 2013년
◦
총 리뷰 수 ≤ 24
◦
예약 가능 일수 = 0
5. 조건 5
•
2014년 리뷰가 53개 이하 & 예약 불가
◦
last_review가 2014년
◦
총 리뷰 수 ≤ 53
◦
예약 가능 일수 = 0
import pandas as pd
# 데이터 불러오기
# 날짜 컬럼 변환
df['last_review'] = pd.to_datetime(df['last_review'], errors='coerce')
# 조건별 필터링
cond1 = (
(df['number_of_reviews'] == 0) &
(df['last_review'].isnull()) &
(df['reviews_per_month'].isnull()) &
(df['availability_365'] == 0)
)
cond2 = (
(df['last_review'].dt.year == 2011) &
(df['number_of_reviews'] == 1) &
(df['availability_365'].isin([0, 1]))
)
cond3 = (
(df['last_review'].dt.year == 2012) &
(df['number_of_reviews'] <= 6) &
(df['availability_365'] == 0)
)
cond4 = (
(df['last_review'].dt.year == 2013) &
(df['number_of_reviews'] <= 24) &
(df['availability_365'] == 0)
)
cond5 = (
(df['last_review'].dt.year == 2014) &
(df['number_of_reviews'] <= 53) &
(df['availability_365'] == 0)
)
# 조건별 개수 출력용 데이터프레임 생성
counts = {
"조건 1: 리뷰 없음 & 리뷰날짜 없음 & 한달 리뷰 없음 & 예약가능일수 0": cond1.sum(),
"조건 2: 2011년 리뷰 1개 & 예약가능일수 0 또는 1": cond2.sum(),
"조건 3: 2012년 리뷰 6개 이하 & 예약가능일수 0": cond3.sum(),
"조건 4: 2013년 리뷰 24개 이하 & 예약가능일수 0": cond4.sum(),
"조건 5: 2014년 리뷰 53개 이하 & 예약가능일수 0": cond5.sum(),
"총합": (cond1 | cond2 | cond3 | cond4 | cond5).sum()
}
counts_df = pd.DataFrame.from_dict(counts, orient='index', columns=['숙소 수'])
counts_df.index.name = '비운영 조건'
# 비운영 조건별 카운트 정리
counts = {
"조건 1": cond1.sum(),
"조건 2": cond2.sum(),
"조건 3": cond3.sum(),
"조건 4": cond4.sum(),
"조건 5": cond5.sum(),
"총합": (cond1 | cond2 | cond3 | cond4 | cond5).sum()
}
counts_df = pd.DataFrame.from_dict(counts, orient='index', columns=['숙소 수'])
counts_df.index.name = '비운영 조건'
# 깔끔한 출력 (Colab 전용)
print("✅ 비운영 조건별 숙소 수")
print(counts_df.to_string())
Python
복사
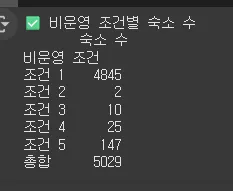
10052개 중 “5207개 판단“
⇒ 신규 일 확률이 있다! 보류!!!
보류 판단 조건 1
•
number_of_reviews = 0
→ 지금까지 받은 총 리뷰 수가 0개
•
last_review = NaN
→ 마지막 리뷰 날짜가 없음 (즉, 리뷰 기록 자체가 없음)
•
reviews_per_month = NaN
→ 월 평균 리뷰 수가 없음 (리뷰가 없기 때문에 자동으로 NaN)
•
availability_365 ≠ 0
→ 연중 예약 가능일 수가 1일 이상
⇒ host_id 기준으로 해당 호스트가 가진 숙소 대부분이 비슷한 상태
⇒ 미운영으로 판단 하는 host_id 기준을 판단해서, 대부분이 비슷한 상태라고. 확인 되면 미운영으로 판단
stop
상관관계
'number_of_reviews' vs availability_365
# 상관계수 계산
correlation = df['number_of_reviews'].corr(df['availability_365'])
print("📊 리뷰 수와 예약 가능일 수의 관계 분석")
print(f"✅ 상관계수 (Pearson): {round(correlation, 3)}")
# 평균 및 분위수 확인
summary = df[['number_of_reviews', 'availability_365']].describe(percentiles=[0.25, 0.5, 0.75])
print("\n📋 통계 요약 (number_of_reviews vs availability_365):")
print(summary)
Python
복사
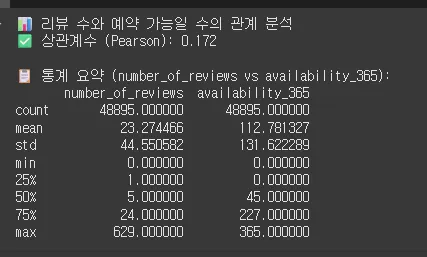
→ 전반적으로는 '열려있는 날이 많을수록 리뷰도 좀 더 많아지는 경향은 있음'
1. 상관관계는 낮다 (0.172)
•
피어슨 상관계수 0.172는 매우 약한 양의 상관관계입니다.
•
즉, 리뷰 수가 많다고 해서 예약 가능일 수가 반드시 많지는 않다는 뜻입니다.
•
리뷰 수가 많음 = 인기가 많을 수 있음이지만, 예약 가능일 수는 그만큼 일정하지 않음.
2. 예약 가능일 수는 편차가 크다
항목 | 예약 가능일 수 (availability_365) |
평균 | 112.78일 (연간 약 31%) |
중앙값 | 45일 |
최대 | 365일 |
최소 | 0일 (예약 안받는 숙소도 존재) |
표준편차 | 131.62 → 매우 다양함 |
→ 일부는 1년 내내 열어두고, 일부는 거의 운영하지 않음.
즉, 운영 전략이 천차만별이라는 걸 의미합니다.
but
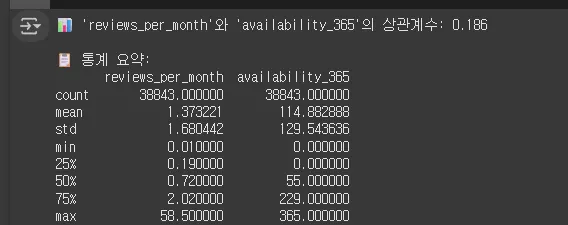
reviews_per_month 와 'availability_365
# 결측치 제거
filtered_df = df[['reviews_per_month', 'availability_365']].dropna()
# 상관계수 계산 (Pearson)
correlation = filtered_df['reviews_per_month'].corr(filtered_df['availability_365'])
# 통계 요약 출력
print(f"📊 'reviews_per_month'와 'availability_365'의 상관계수: {round(correlation, 3)}\n")
print("📋 통계 요약:")
print(filtered_df.describe())
Python
복사
last_review 연도 추출
# last_review에서 연도만 추출
df['review_year'] = df['last_review'].dt.year
# 연도별 리뷰 수 분포 계산
review_year_counts = df['review_year'].value_counts().sort_index()
review_year_counts
Python
복사
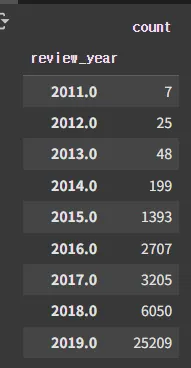
10052 의 넓은 제거하고 판단 해야 함.
실행 및 진행 사항 정리
결과