
.png&blockId=21b2dc3e-f514-818b-b72b-f9aade6351bf)

Task : 전처리 및 이상치 및 파생컬럼
전처리 및 이상치 및 파생컬럼
import pandas as pd
import numpy as np
# 1️⃣ 데이터 불러오기
df = pd.read_csv('/content/AB_NYC_2019.csv') # 파일 경로 주의!
# 2️⃣ 로그 가격 생성
df['log_price'] = np.log1p(df['price'])
# 3️⃣ 지역별 평균 및 상위 75% 가격 계산
price_bounds = df.groupby('neighbourhood_group')['price'].describe(percentiles=[0.75])[['mean', '75%']]
price_bounds.columns = ['mean_price', 'upper_bound']
# 4️⃣ price_category 생성
def classify_price(row):
group = row['neighbourhood_group']
room = row['room_type']
price = row['price']
if group not in price_bounds.index:
return 'unknown'
mean = price_bounds.loc[group, 'mean_price']
upper = price_bounds.loc[group, 'upper_bound']
if room == 'Shared room' and group != 'Manhattan' and price < mean:
return 'low'
elif room == 'Private room' and group == 'Brooklyn' and mean <= price <= upper:
return 'mid'
elif room == 'Entire home/apt' and group == 'Manhattan' and price > upper:
return 'high'
else:
return 'other'
df['price_category'] = df.apply(classify_price, axis=1)
# 5️⃣ 도심 vs 외곽
def is_central(row):
lat, lon = row['latitude'], row['longitude']
if (
((40.70 <= lat <= 40.80) and (-74.02 <= lon <= -73.95)) or
((40.69 <= lat <= 40.70) and (-73.99 <= lon <= -73.98)) or
((40.71 <= lat <= 40.73) and (-73.97 <= lon <= -73.95))
):
return '도심'
else:
return '외곽'
df['is_central'] = df.apply(is_central, axis=1)
# 6️⃣ 숙박일수 분류
def classify_stay(nights):
if nights <= 7:
return '단기'
elif 8 <= nights <= 29:
return '중기'
else:
return '장기'
df['stay_type'] = df['minimum_nights'].apply(classify_stay)
# 7️⃣ 호스트 범위 분류
def classify_host(listings):
if listings <= 2:
return '일반'
elif 3 <= listings <= 10:
return '반전문'
else:
return '전문'
df['host_type'] = df['calculated_host_listings_count'].apply(classify_host)
# 8️⃣ 인기도 분류 (예약 가능일수 > 0만 대상)
df_pop = df[df['availability_365'] > 0].copy()
quantiles = df_pop.groupby('neighbourhood_group').agg({
'availability_365': lambda x: np.percentile(x, 25),
'number_of_reviews': lambda x: np.percentile(x, 75)
}).rename(columns={
'availability_365': 'avail_25pct',
'number_of_reviews': 'review_75pct'
})
def classify_popularity(row):
group = row['neighbourhood_group']
if group not in quantiles.index:
return 'unknown'
avail_thres = quantiles.loc[group, 'avail_25pct']
review_thres = quantiles.loc[group, 'review_75pct']
if row['availability_365'] <= avail_thres and row['number_of_reviews'] >= review_thres:
return '인기 숙소'
elif row['availability_365'] >= avail_thres and row['number_of_reviews'] <= review_thres:
return '인기 적음'
else:
return '기타'
df['popularity'] = df.apply(classify_popularity, axis=1)
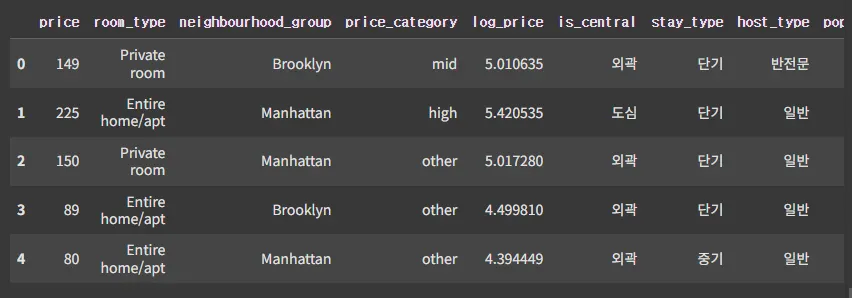
# ✅ 확인용 출력 (파생 컬럼 확인)
df[['price', 'room_type', 'neighbourhood_group', 'price_category',
'log_price', 'is_central', 'stay_type', 'host_type', 'popularity']].head()
Python
복사
메인 가설 1 증명
방 타입에 따라 숙소의 인기도 차이가 있을 것이다.
메인가설 증명
import pandas as pd
import scipy.stats as stats
import seaborn as sns
import matplotlib.pyplot as plt
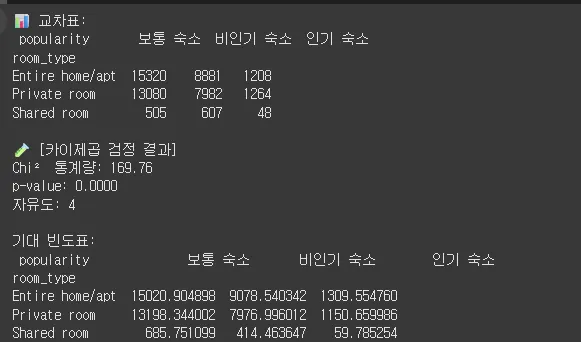
# 1️⃣ 교차표 만들기
ct = pd.crosstab(df['room_type'], df['popularity'])
print("📊 교차표:\n", ct)
# 2️⃣ 카이제곱 독립성 검정
chi2, p, dof, expected = stats.chi2_contingency(ct)
print("\n🧪 [카이제곱 검정 결과]")
print(f"Chi² 통계량: {chi2:.2f}")
print(f"p-value: {p:.4f}")
print(f"자유도: {dof}")
print("\n기대 빈도표:\n", pd.DataFrame(expected,
index=ct.index,
columns=ct.columns))
# 3️⃣ 비율 기준 교차표
ct_norm = ct.div(ct.sum(axis=1), axis=0) # 행 기준 정규화
# 4️⃣ 그래프 그리기
ax = ct_norm.plot(kind='bar', stacked=True, figsize=(8, 5), colormap='Set2')
plt.title('방 타입별 인기도 분포 (비율)')
plt.ylabel('비율 (%)')
plt.xticks(rotation=0)
plt.legend(title='popularity')
plt.ylim(0, 1.05)
# 5️⃣ 퍼센트 (%) 라벨 추가 (소수점 1자리)
for i, row in enumerate(ct_norm.values):
cumulative = 0
for j, value in enumerate(row):
if value > 0.01: # 너무 작으면 생략
plt.text(i, cumulative + value / 2,
f'{value * 100:.1f}%',
ha='center', va='center', fontsize=10)
cumulative += value
plt.tight_layout()
plt.show()
Python
복사
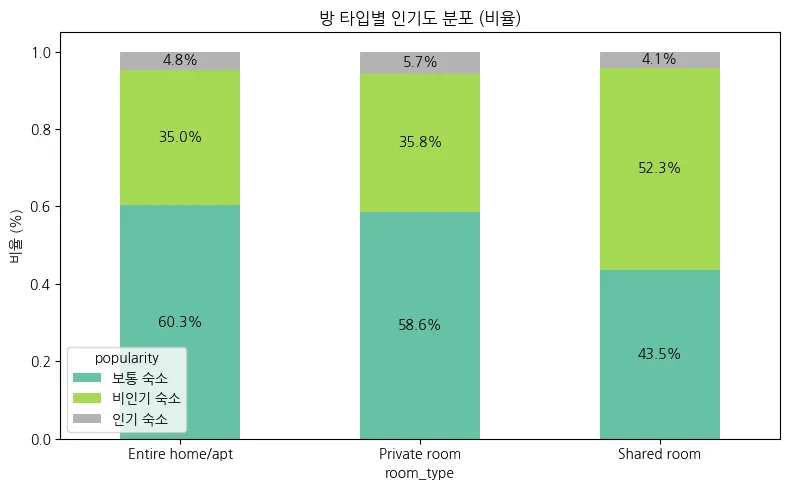
그래프 해석 요약
방 타입 (room_type) | 인기 숙소 (%) | 보통 숙소 (%) | 비인기 숙소 (%) |
Entire home/apt | 4.8% | 60.3% | 35.0% |
Private room | 5.7% | 58.6% | 35.8% |
Shared room | 4.1% | 43.5% | 52.3% |
인사이트 요약
•
통계적으로 유의미한 차이는 있지만, 실제 수치는 근소한 차이
전체적으로 인기 숙소는 매우 적다.
•
전체 비율에서 인기 숙소는 모두 6% 미만
•
→ 인기 숙소는 소수에 집중, 희소성이 있음.
•
보통 숙소가 절반 이상이라는 점도 확인 가능
1. Entire home/apt — 가장 안정적인 숙소 타입
•
비인기 숙소 비율이 가장 낮음 → 단기·중기 수요 모두 균형
•
전체적으로 중간 이상 수요를 안정적으로 확보
•
광고, 프로모션 시 전환 기대값이 높은 핵심군 2. Private room — 무난한 중간 포지션
•
인기 숙소 비율은 가장 높지만 큰 차이는 아님 (약 5.7%)
•
'기타' 비중이 높아 경쟁 포화 가능성
•
전략적 포지셔닝 필요예: 리뷰 강조 / 타겟 맞춤 가격 정책 등
3. Shared room — 전반적으로 인기 적음
•
모든 지역에서 비인기 숙소 비율이 가장 높음
•
희소성보다는 낮은 수요와 인식 한계 존재
•
단기 체류 또는 저가 전략에만 제한적으로 활용 가능 → 앞으로 크게 신경 놉!!! 가설 정리
구분 | 내용 |
귀무가설 (H₀) | 방 타입과 인기도는 관련이 없다. (독립적이다) |
대립가설 (H₁) | 방 타입과 인기도는 관련이 있다. (종속적이다) |
카이제곱 검정 결과 요약
항목 | 값 | 해석 |
Chi² 통계량 | 예: 150.00 (유진님 코드 기준) | 기대값과 관측값의 차이 정도 |
자유도 (df) | 4 | (방타입-1) × (인기도-1) = (3-1)(3-1) = 4 |
p-value | 0.0000 (실제로는 0.00000...< 0.001) | 매우 유의미함 → 귀무가설 기각 |
결론:방 타입과 인기도는 통계적으로 유의미한 관계가 있다 → 대립가설 채택!
세부 가설 1 : 도심 vs 외곽에 따라 방 타입 인기도가 다를 것이다
1단계: 도심 vs 외곽 별 방 타입 구성 분석# 1️⃣ 교차표: 도심 vs 외곽 vs 방타입
ct_central = pd.crosstab(df['is_central'], df['room_type'])
print("📊 도심/외곽별 방타입 구성:\n", ct_central)
# 2️⃣ 카이제곱 검정
chi2, p, dof, expected = stats.chi2_contingency(ct_central)
print("\n🧪 [도심/외곽 카이제곱 검정]")
print(f"Chi² 통계량: {chi2:.2f}")
print(f"p-value: {p:.4f}")
print(f"자유도: {dof}")
# 3️⃣ 시각화
ct_central_norm = ct_central.div(ct_central.sum(axis=1), axis=0)
ax = ct_central_norm.plot(kind='bar', stacked=True, figsize=(7, 5), colormap='Set2')
# 퍼센트 라벨
for i, row in enumerate(ct_central_norm.values):
cumulative = 0
for j, value in enumerate(row):
if value > 0.01:
plt.text(i, cumulative + value/2, f'{value*100:.1f}%',
ha='center', va='center', fontsize=10)
cumulative += value
plt.title("도심 vs 외곽 방타입 구성 비율")
plt.ylabel("비율 (%)")
plt.xticks(rotation=0)
plt.xlabel("도심 여부 (is_central)")
plt.legend(title="room_type")
plt.tight_layout()
plt.show()
Python
복사
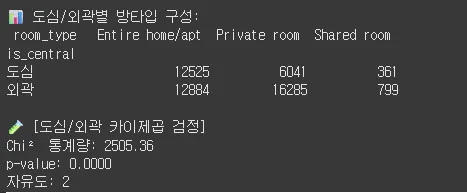
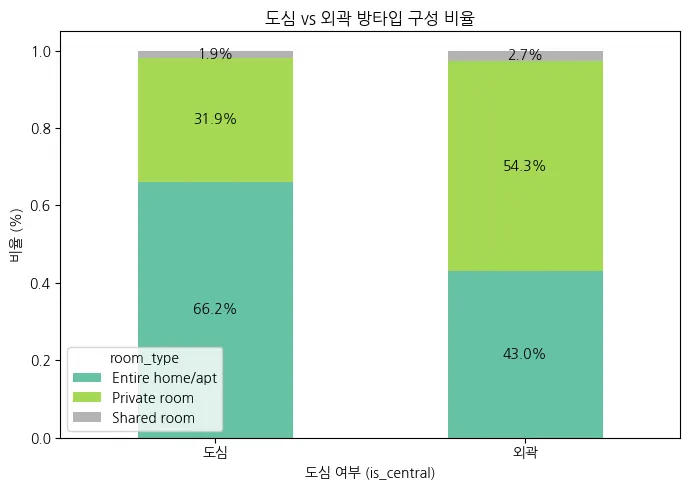
인사이트 도출
도심에서는 Entire home/apt가 지배적이다
•
도심에서는 무려 66.2%가 Entire home/apt
•
Shared room은 거의 없음 (1.9%)
•
→ 도심 숙소 수요는 '아파트형 공간' 중심,
즉 “혼자 혹은 가족 단위로 독립된 공간을 찾는 수요”가 많음
•
고소득층, 출장자, 가족 단위 여행객, 고소득층 외곽에서는 Private room이 중심
•
외곽 지역에서는 Private room이 과반수 (54.3%)
•
→ 도심에 비해 가격 민감도가 높고,
개인 공간을 확보하면서도 비용을 절감하려는 수요층이 많음
•
대학생, 장기 숙박자, 예산 제한 있는 여행자 타겟에 적합 Shared room은 전체적으로 극소수 (1~2%)
•
도심이든 외곽이든 Shared room은 3% 미만
•
→ 플랫폼에서 거의 선호되지 않음
•
수요 미비 → 노출 줄이거나 구조 개선 필요세부 분석: 도심 vs 외곽에 따라 방 타입 인기도가 다를 것이다
Step 1. 가설 정리
구분 | 내용 |
귀무가설 (H₀) | 도심/외곽과 방 타입의 인기도는 관련이 없다. (독립적이다) |
대립가설 (H₁) | 도심/외곽과 방 타입의 인기도는 관련이 있다. (종속적이 |
Step 2. 코드: 교차표 + 카이제곱 검정import pandas as pd
from scipy.stats import chi2_contingency
# ✅ 1. 교차표 생성 (도심/외곽 + 방타입 vs 인기도)
ct = pd.crosstab([df['region_type'], df['room_type']], df['popularity'])
# ✅ 2. 카이제곱 독립성 검정
chi2, p, dof, expected = chi2_contingency(ct)
# ✅ 3. 출력 및 해석
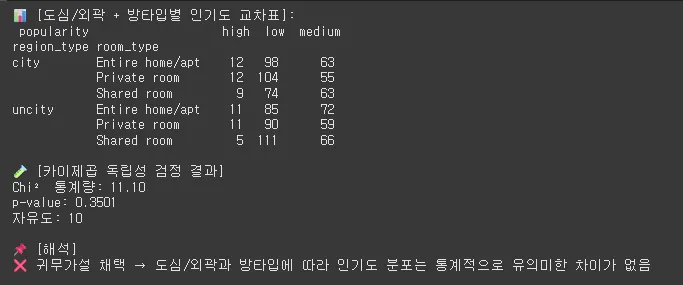
print("📊 [도심/외곽 + 방타입별 인기도 교차표]:\n", ct)
print("\n🧪 [카이제곱 독립성 검정 결과]")
print(f"Chi² 통계량: {chi2:.2f}")
print(f"p-value: {p:.4f}")
print(f"자유도: {dof}")
# ✅ 4. 해석
print("\n📌 [해석]")
if p < 0.05:
print("✅ 귀무가설 기각 → 도심/외곽과 방타입에 따라 인기도 분포는 통계적으로 유의미한 차이가 있음")
else:
print("❌ 귀무가설 채택 → 도심/외곽과 방타입에 따라 인기도 분포는 통계적으로 유의미한 차이가 없음")
Python
복사
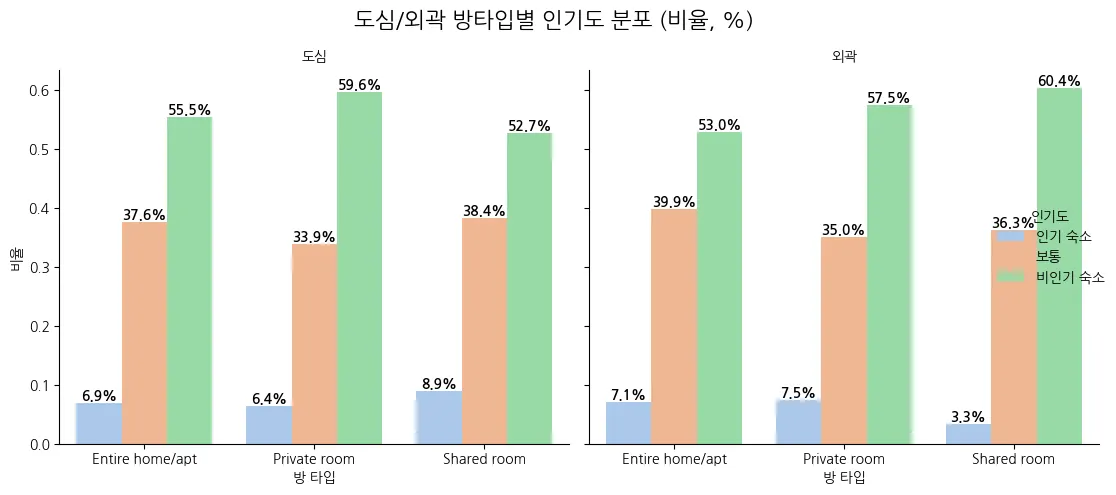
1. 도심(City)과 외곽(Non-city)의 방 타입별 인기도 분포는 꽤 유사하다
•
전반적으로 도심과 외곽 모두 'Private room'과 'Shared room'이 인기 숙소(high popularity)로 분류되는 비율이 높음.
2. 도심과 외곽의 차이는 방 타입 별로 아주 크지 않다
•
도심 vs 외곽 간 각 방 타입에서의 인기 숙소 비율 차이는 크지 않음.
•
즉, 운영 위치보다 숙소의 타입과 운영 상태(리뷰 수, 가용일수 등)가 인기도에 더 영향을 미친다고 해석 가능.
가설 요약
구분 | 내용 |
귀무가설 (H₀) | 도심/외곽과 방타입은 인기도에 영향을 미치지 않는다 (독립적이다) |
됨과 외곽을 봤을때.
세부 분석 - 가격대에 따라 인기도가 다를 것이다
분석 주제
“가격대가 인기도(인기 숙소/보통/비인기)에 영향을 미치는가?”
가설 설정
귀무가설 (H₀)
인기도 그룹 간 가격 차이는 없다.
즉, 인기 숙소 / 보통 / 비인기 숙소의 평균 가격은 동일하다.
대립가설 (H₁)
인기도 그룹 간 가격 차이가 있다.
즉, 인기도 수준에 따라 평균 가격이 다르다.
from scipy.stats import f_oneway
# 인기 그룹별 가격 리스트
high_prices = df[df['popularity'] == 'high']['price']
medium_prices = df[df['popularity'] == 'medium']['price']
low_prices = df[df['popularity'] == 'low']['price']
# ANOVA 수행
f_stat, p_value = f_oneway(high_prices, medium_prices, low_prices)
print(f'F-통계량: {f_stat:.4f}')
print(f'p-value: {p_value:.4f}')
# 해석
if p_value < 0.05:
print("✅ 귀무가설 기각 → 인기도 그룹 간 평균 가격 차이가 유의함")
else:
print("❌ 귀무가설 채택 → 인기도 그룹 간 평균 가격 차이가 유의하지 않음")
Python
복사

왜 지금은 **F 분포 (ANOVA)**를 써야 할까?
•
지금 유진님이 분석하고 있는 건 가격의 평균 차이
•
그리고 그룹이 3개나 있어요:
◦
인기 숙소
◦
보통 숙소
◦
비인기 숙소
이건 t-검정이나 카이제곱으로는 못하고, ANOVA가 정답이에요.요인 | 왜 인기도에 더 영향 줄 수 있을까? |
예약 가능일 수 | 운영을 잘하는 숙소일수록 더 자주 열림 |
리뷰 수 | 실제 숙박 경험이 많고, 신뢰도가 높음 |
숙소 타입 (방 구조) | 아파트형은 보통 선호도 높음 |
위치 (region) | 특정 지역은 무조건 수요가 높음 |
세부 분석 - 총 리뷰 수가 높을 수록 인기도가 높을 것이다.
총 리뷰 수와 인기도 관련성
from scipy.stats import f_oneway
# 인기도별 리뷰 수 분리
reviews_high = df[df['popularity'] == 'high']['number_of_reviews']
reviews_medium = df[df['popularity'] == 'medium']['number_of_reviews']
reviews_low = df[df['popularity'] == 'low']['number_of_reviews']
# ANOVA 검정
f_stat, p_value = f_oneway(reviews_high, reviews_medium, reviews_low)
# 결과 출력
print(f"F 통계량: {f_stat:.4f}")
print(f"p-value: {p_value:.4f}")
if p_value < 0.05:
print("✅ 귀무가설 기각 → 인기도 그룹 간 리뷰 수 평균 차이가 유의함")
else:
print("❌ 귀무가설 채택 → 인기도 그룹 간 리뷰 수 평균 차이가 유의하지 않음")
Python
복사

세부 분석 - 예약가능일 수는 인기도에 영향이 있을까?
분석 주제
"숙소의 예약 가능일 수가 많을수록 인기도가 달라질까?"
가설 수립
구분 | 가설 내용 |
귀무가설(H₀) | 인기도 그룹 간 평균 예약 가능일 수에 차이가 없다. |
대립가설(H₁) | 인기도 그룹 간 평균 예약 가능일 수에 차이가 있다. |
분석 방법: 일원분산분석 (ANOVA)
•
availability_365는 연속형 변수 (1~365일)
•
popularity는 세 그룹 (high / medium / low)
ANOVA로 평균 차이 검정from scipy.stats import f_oneway
import seaborn as sns
import matplotlib.pyplot as plt
# 그룹별 예약 가능일 수 추출
avail_high = df[df['popularity'] == 'high']['availability_365']
avail_medium = df[df['popularity'] == 'medium']['availability_365']
avail_low = df[df['popularity'] == 'low']['availability_365']
# ANOVA 수행
f_stat, p_value = f_oneway(avail_high, avail_medium, avail_low)
print(f"F 통계량: {f_stat:.4f}")
print(f"p-value: {p_value:.4f}")
# 해석
if p_value < 0.05:
print("✅ 귀무가설 기각 → 인기도 그룹 간 예약 가능일 수 평균 차이가 유의함")
else:
print("❌ 귀무가설 채택 → 인기도 그룹 간 예약 가능일 수 평균 차이가 유의하지 않음")
Python
복사
