.png&blockId=21b2dc3e-f514-818b-b72b-f9aade6351bf)

Task : 가설 설정하고 검증하기
가설 설정 : 일단 세 가지 가설 요렇게 세웠구요
1.
도심은 외곽보다 월 별 리뷰 수가 많고, 월 예상 수익도 클 것이다.
2.
같은 상위 숙소라도 Entire room/apt의 평균 가격이 Private, Shared의 평균 가격보다 높을 것이다.
3.
하위 25% 숙소의 최소 숙박일 수가 상위 25%의 최소 숙박일 수보다 클 것이다.
실행 및 진행 사항 정리
# 비교할 컬럼
compare_cols = ['price', 'minimum_nights', 'availability_365',
'reviews_per_month', 'estimated_revenue_per_month', 'daily_guests']
# 도심/외곽
city_groups = []
for region in df_filtered['city_and_suburb'].dropna().unique():
group = df_filtered[df_filtered['city_and_suburb'] == region]
top = group[group['popularity_score'] >= group['popularity_score'].quantile(0.75)]
bottom = group[group['popularity_score'] <= group['popularity_score'].quantile(0.25)]
top_means = top[compare_cols].mean().rename(f"{region}_상위 25%")
bottom_means = bottom[compare_cols].mean().rename(f"{region}_하위 25%")
city_groups.append(pd.concat([top_means, bottom_means], axis=1))
city_comparison = pd.concat(city_groups, axis=1)
city_comparison.round(1)
Python
복사
# 룸타입
room_groups = []
for room in df_filtered['room_type'].dropna().unique():
group = df_filtered[df_filtered['room_type'] == room]
top = group[group['popularity_score'] >= group['popularity_score'].quantile(0.75)]
bottom = group[group['popularity_score'] <= group['popularity_score'].quantile(0.25)]
top_means = top[compare_cols].mean().rename(f"{room}_상위 25%")
bottom_means = bottom[compare_cols].mean().rename(f"{room}_하위 25%")
room_groups.append(pd.concat([top_means, bottom_means], axis=1))
room_comparison = pd.concat(room_groups, axis=1)
room_comparison.round(1)
Python
복사
결과
컬럼 평균 | 외곽_상위 25% | 외곽_하위 25% | 도심_상위 25% | 도심_하위 25% |
price | 119.4 | 109.1 | 197.2 | 164.873426 |
minimum_nights | 3.2 | 5.4 | 4.0 | 6.6 |
availability_365 | 161.1 | 55.8 | 145.1 | 40.5 |
reviews_per_month | 3.8 | 0.1 | 3.4 | 0.1 |
estimated_revenue_per_month | 11272.8 | 947.7 | 20466.6 | 2271.6 |
daily_guests | 0.9 | 0.001812 | 0.8 | 0.000840 |
컬럼 평균 | Private room_
상위 25% | Private room_
하위 25% | Entire home/apt_
상위 25% | Entire home/apt_
하위 25% | Shared room_
상위 25% | Shared room_
하위 25% |
price | 88.3 | 89.6 | 203.9 | 186.9 | 64.6 | 92.3 |
minimum_nights | 3.3 | 4.6 | 3.7 | 7.2 | 1.9 | 6.5 |
availability_365 | 146.1 | 47.9 | 160.2 | 41.7 | 163.6 | 124.2 |
reviews_per_month | 3.8 | 0.1 | 3.5 | 0.1 | 3.6 | 0.2 |
estimated_revenue_per_month | 7395.9 | 1242.9 | 22091.0 | 2004.0 | 3184.6 | 489.0 |
daily_guests | 0.9 | 0.002262 | 0.9 | 0.000785 | 0.9 | 0.0 |
1. 도심은 외곽보다 월 별 리뷰 수가 많고, 월 예상 수익도 클 것이다.
•
월 예상 수익은 추측했던 대로 도심이 우수 숙소와 비우수 숙소 둘 다 외곽에 비해 두 배 가량 높은 것을 볼 수 있었다. 근데 가격 좀 이상한 것 같기도 하고
•
하지만, 상위 25%에서 월 별 리뷰 수는 외곽이 도심보다 더 크게 집계되었다.
2.
우수 숙소 안에서도 Entire room/apt의 평균 가격이 Private, Shared의 평균 가격보다 높을 것이다.
•
같은 우수 숙소라도 룸 타입에 따라 평균 가격이 2배 이상의 차이가 나는 것을 볼 수
있기 때문에 더욱 더 룸 타입 별로 나눠서 분석하고 룸 타입에 따라 다른 해결 방안을
제시해야겠다고 생각했다.
3.
하위 25% 숙소의 최소 숙박일 수가 상위 25%의 최소 숙박일 수보다 클 것이다.
•
확실히 도심과 외곽, 룸 타입 별로 모두 비교해 보아도 상위 25% 숙소의 최소 숙박일
수보다 하위 25% 숙소의 최소 숙박일 수가 더 크다는 것을 알 수 있었고, 상위 숙소와
하위 숙소에서 가장 큰 나이가 난 범주는 room_type에서 Shared room이었다.
compare_cols = ['price', 'minimum_nights', 'availability_365',
'reviews_per_month', 'estimated_revenue_per_month', 'daily_guests']
combinations = df_filtered[['city_and_suburb', 'room_type']].dropna().drop_duplicates()
result = []
for _, row in combinations.iterrows():
region = row['city_and_suburb']
room = row['room_type']
group = df_filtered[(df_filtered['city_and_suburb'] == region) & (df_filtered['room_type'] == room)]
if len(group) < 10:
continue # 데이터 너무 적으면 스킵
top = group[group['popularity_score'] >= group['popularity_score'].quantile(0.75)]
bottom = group[group['popularity_score'] <= group['popularity_score'].quantile(0.25)]
top_mean = top[compare_cols].mean()
bottom_mean = bottom[compare_cols].mean()
row_df = pd.DataFrame({
'조합': f'{region}_{room}',
'상위25_price': top_mean['price'],
'하위25_price': bottom_mean['price'],
'상위25_min_nights': top_mean['minimum_nights'],
'하위25_min_nights': bottom_mean['minimum_nights'],
'상위25_avail': top_mean['availability_365'],
'하위25_avail': bottom_mean['availability_365'],
'상위25_reviews': top_mean['reviews_per_month'],
'하위25_reviews': bottom_mean['reviews_per_month'],
'상위25_revenue': top_mean['estimated_revenue_per_month'],
'하위25_revenue': bottom_mean['estimated_revenue_per_month'],
'상위25_guests': top_mean['daily_guests'],
'하위25_guests': bottom_mean['daily_guests'],
}, index=[0])
result.append(row_df)
summary_df = pd.concat(result, ignore_index=True)
summary_df
Python
복사
조합 | 상위25_price | 하위25_price | 상위25_min_nights | 하위25_min_nights | 상위25_avail | 하위25_avail | 상위25_reviews | 하위25_reviews | 상위25_revenue | 하위25_revenue | 상위25_guests | 하위25_guests |
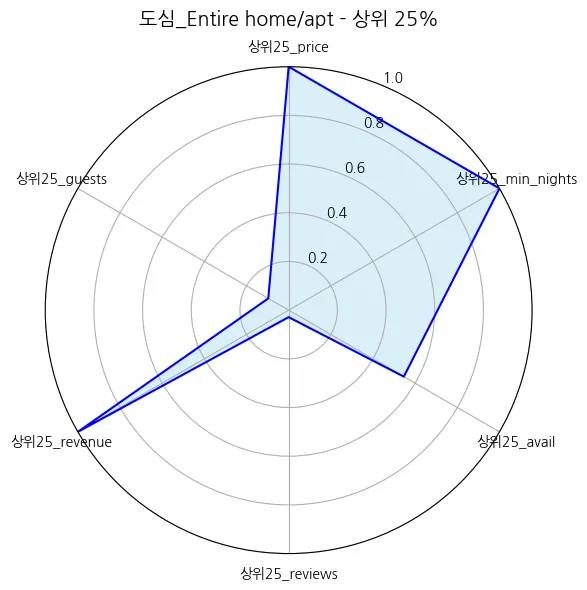
도심_Entire home/apt | 254.226653 | 206.926029 | 4.300105 | 8.090370 | 154.430570 | 42.971389 | 3.124914 | 0.135363 | 27930.570759 | 2560.115248 | 0.766352 | 0.000349 |
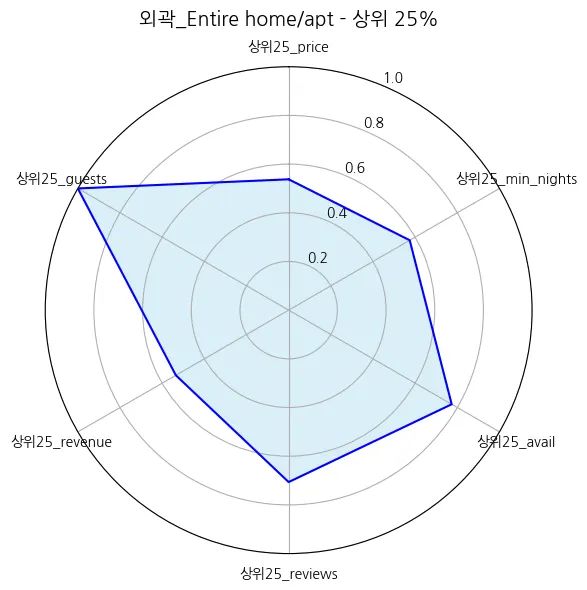
외곽_Entire home/apt | 154.435132 | 157.789497 | 3.085154 | 6.005386 | 164.807847 | 41.492819 | 3.878292 | 0.143483 | 15732.050290 | 1242.947711 | 0.977263 | 0.000898 |
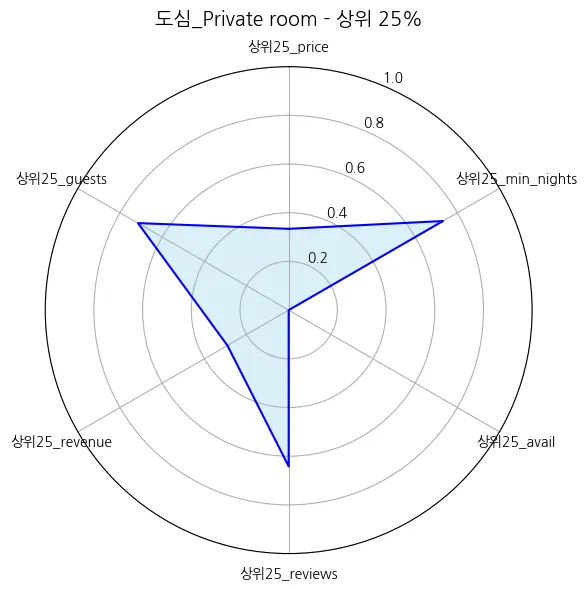
도심_Private room | 110.519581 | 108.341975 | 3.535576 | 4.437948 | 129.452841 | 35.656371 | 3.806917 | 0.141539 | 9314.754550 | 1915.798180 | 0.910645 | 0.001103 |
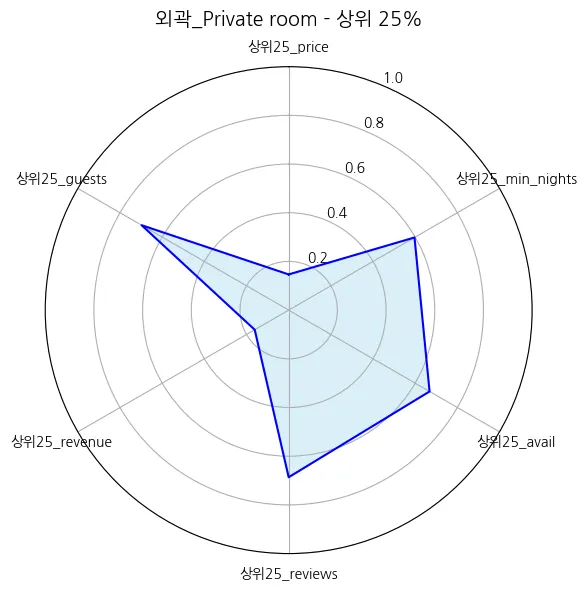
외곽_Private room | 70.091775 | 74.827203 | 3.149657 | 4.709579 | 160.005712 | 59.574330 | 3.856329 | 0.147751 | 5918.526504 | 773.386207 | 0.906702 | 0.002682 |
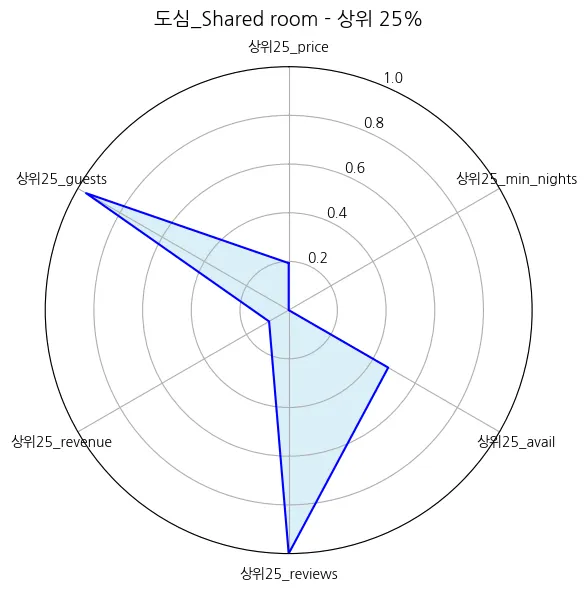
도심_Shared room | 80.117021 | 97.173913 | 1.446809 | 2.989130 | 151.031915 | 76.000000 | 4.205000 | 0.212500 | 4129.896809 | 573.272826 | 0.968085 | 0.000000 |
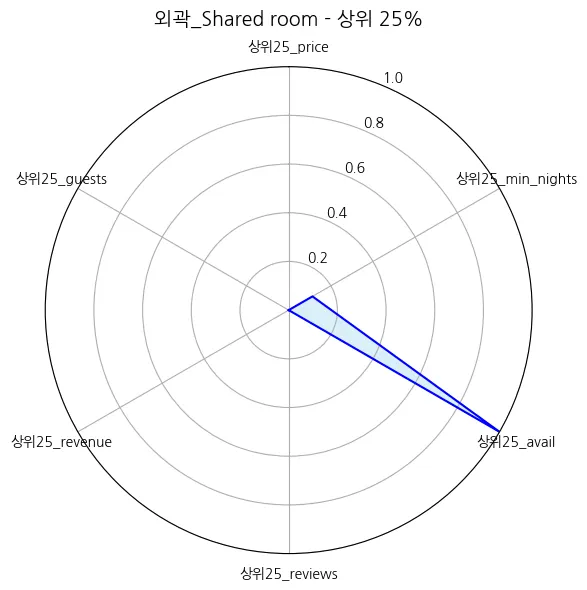
외곽_Shared room | 38.462810 | 88.466667 | 1.768595 | 9.058333 | 175.173554 | 160.166667 | 3.092893 | 0.141917 | 1691.539669 | 421.640833 | 0.743802 | 0.000000 |
summary_df['revenue_gap_ratio'] = summary_df['상위25_revenue'] / summary_df['하위25_revenue']
조합 | revenue_gap_ratio |
도심_Entire home/apt | 10.91 |
외곽_Entire home/apt | 12.66 |
도심_Private room | 4.86 |
외곽_Private room | 7.65 |
도심_Shared room | 7.20 |
외곽_Shared room | 4.01 |
summary_df['guest_gap_ratio'] = summary_df['상위25_guests'] / summary_df['하위25_guests']
조합 | guest_gap_ratio |
도심_Entire home/apt | 2196.36 |
외곽_Entire home/apt | 1088.67 |
도심_Private room | 825.50 |
외곽_Private room | 338.07 |
도심_Shared room | inf(하위25가 0) |
외곽_Shared room | inf(하위25가 0) |
summary_df['review_gap_ratio'] = summary_df['상위25_reviews'] / summary_df['하위25_reviews']
조합 | review_gap_ratio |
도심_Entire home/apt | 23.09 |
외곽_Entire home/apt | 27.03 |
도심_Private room | 26.90 |
외곽_Private room | 26.10 |
도심_Shared room | 19.79 |
외곽_Shared room | 21.79 |
PPT 흐름 개요:
1.
데이터 기반 인기 점수 정의
2.
조합 별 상·하위 숙소의 특성 비교
3.
리뷰/수익/예약일 수에서 큰 차이를 보이는 조합 발견
4.
광고 및 운영 전략 도출
5.
예측 모델을 통한 향후 전략 자동화 가능성 제시