

01. 개요

 서울시 부동산 실거래가 데이터를 분석하여 고객 맞춤형 매물 추천 및 매매 전략을 제시하세요!
서울시 부동산 실거래가 데이터를 분석하여 고객 맞춤형 매물 추천 및 매매 전략을 제시하세요!•
서울시 부동산 실거래가 정보는 실제 거래 신고 기반의 데이터입니다.
•
이 데이터는 어느 자치구·법정동에서 어떤 건물이 언제, 얼마에 거래되었는지를 기록합니다.
•
분석가는 이를 통해 거주 안정성·투자 가치·매도 타이밍 등 실제 고객 의사결정에 필요한 인사이트를 도출합니다.
당신은 스파르타 공인중개사의 데이터 애널리스트 겸 에이스 공인중개사입니다!•
2018~2024년 기간의 거래 데이터를 활용해, 고객 유형별 맞춤형 매물 추천 전략을 수립해야 합니다.
02. 배경
서울 부동산 데이터의 맥락•
최근 서울 부동산 시장은 금리 변동, 정책 규제, 경기 상황 등으로 인해 거래량과 가격의 변동성이 심화되고 있습니다.
•
고객들은 더 이상 “감각적 추천”에 의존하지 않고, 데이터 기반 근거에 기반한 의사결정을 원합니다.
•
따라서 중개사는 데이터 애널리틱스를 활용하여 매수·매도 타이밍, 지역 안정성, 미래 가치를 제시할 필요가 있습니다.
주요 고객 유형 예시 고객 A (거주 목적 매수 고객)•
자녀 교육과 생활 편의를 위해 안정적인 자치구에서 거주용 아파트를 구매하고자 합니다.
•
예: 평균 거래 금액이 급변하지 않는 안정적인 자치구를 탐색합니다.
•
예: 신축 건물이 많은 지역을 탐색합니다.
•
예: 직장이 몰려있는 광화문, 여의도, 강남 인근 매물을 찾아봅니다.
고객 B (투자 목적 매수 고객)•
미래 가치가 높은 매물과 지역을 발굴하여 투자 전략을 제안합니다.
•
예: 최근 몇 년간 거래 금액이 지속적으로 상승한 지역을 파악합니다.
•
예: 건축 연도에 따른 가격 프리미엄을 분석합니다.
고객 C (매도 희망자)•
이 고객은 보유 주택을 최적의 시점에 매도하고자 합니다.
•
예: 자치구별 월별·분기별 거래량을 분석하여 거래가 집중되는 시기를 도출합니다.
•
예: 매물의 가격과 거래량 변동성을 바탕으로 각 자치구에 맞는 매도 전략을 제시합니다.
03. 주제
“해당 데이터에 대한 EDA를 진행하고 결과를 도출하는(보여주는) 것”으로 생각해주세요. •
데이터 EDA(Exploratory Data Analysis) 는 탐색적 데이터 분석을 의미합니다.
•
EDA 는 크게 이상치/결측치 처리 및 시각화 로 나뉩니다.
•
EDA 프로세스
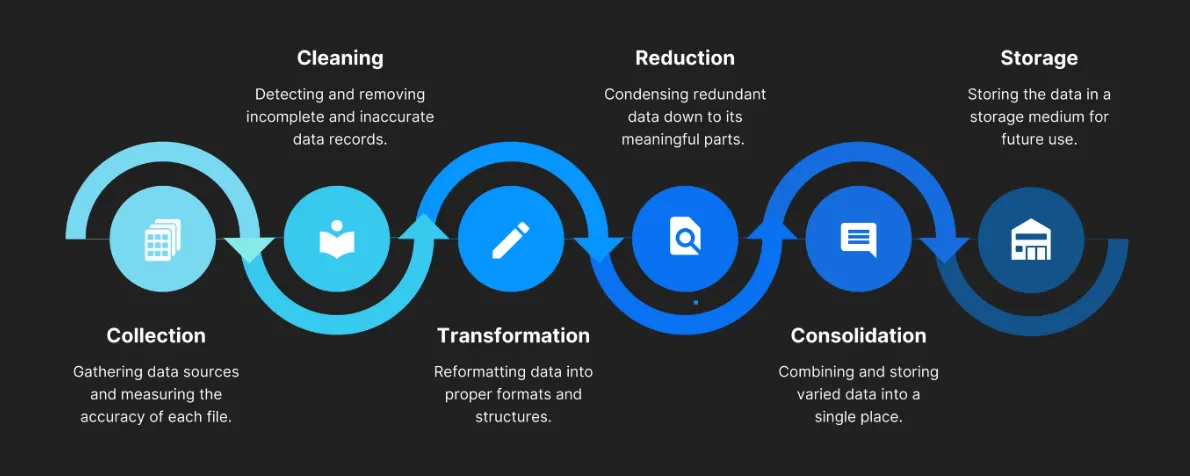 분석 목표
분석 목표•
데이터 EDA
•
데이터 정제 및 전처리
•
데이터 시각화 및 분석
•
데이터 기반 전략 도출
필수 분석 목표[비즈니스 목표 세우기]
[사용된 데이터 소스 설명] 출처, 구성, 관측단위, 주요 변수를 소개하세요.
[EDA] 분석할 데이터의 행/열 개수를 제시하세요.
[EDA] 분석할 데이터의 컬럼 타입과 기술통계(min/median/mean/max, 결측치 수)를 제시하여 EDA를 수행하세요.
[전처리 과정] 결측치/이상치/전처리 처리 규칙을 수립·실행하고, 처리 이유를 적으세요.
[주요 분석제시 및 시각화] 하나 이상의 기준 컬럼을 두고 집계함수로 비교분석 후 시각화하세요
[인사이트 제시] 최소 1개 이상의 인사이트를 수치/그래프/그림/해석으로 제시하세요.
심화 분석 목표필수 분석 이후 더 도전하고 싶은 학생들을 위한 심화 과제입니다. (선택사항)
꼭 아래 문제들이 아니라, 풀고싶은/보여주고 싶은 분석과 인사이트를 보여주셔도 됩니다!
•
EDA를 더 다양한 형식(산점도, 박스플롯 등)으로 나타내보기
고객 A, 고객 B, 고객 C에게 고객 유형별 맞춤 분석
가격 추세 심화 분석
프리미엄 요인 분석
거래량 패턴과 계절성 분석
지역 안정성 & 리스크 분석
심화 시각화 & 파생지표
04. 설명
데이터 개요•
관측 단위: 자치구·법정동 × 매물 단위 거래
•
시간 범위: 2018–2024
•
주요 지표
◦
한글로 작성된 필드명을 아래 데이터 상세사항을 참고하여, 영어 코드명으로 매핑해서 사용하세요.
◦
거래 연도(RCPT_YR), 계약일(CTRT_DAY)
◦
자치구명(CGG_NM), 법정동명(STDG_NM)
◦
건축연도(ARCH_YR), 건물명(BLDG_NM)
◦
거래금액(THING_AMT), 면적(ARCH_AREA, LAND_AREA)
◦
층(FLR), 건물용도(BLDG_USG)
데이터 상세사항 안내 도메인 가이드•
거래금액(THING_AMT): 매물의 핵심 지표. 단위(만원) 표기를 반드시 포함하세요.
•
건축년도(ARCH_YR): 신축/구축 여부에 따라 가격 프리미엄이 크게 달라집니다.
•
자치구 안정성: 평균 거래 금액의 표준편차(변동성)로 안정성을 수치화할 수 있습니다.
•
거래량 패턴: 월별·분기별 거래량 추세를 통해 매도 집중 시기를 포착할 수 있습니다
05. 주의사항
1.
단위 스케일
•
거래금액은 만원 단위, 면적은 m² 단위. 시각화 시 축에 단위 반드시 표기.
2.
결측치·이상치 처리
•
거래 취소(RTRCN_DAY)가 있는 건은 분석에서 제외 권장.
•
극단적으로 낮은/높은 거래금액은 이상치 가능성 검토.
3.
표본 신뢰성
•
특정 연도/지역 거래량이 적은 경우 결과 해석 시 주의 필요.
4.
인과 관계 해석 금지
•
“가격이 올랐다 → 특정 요인 때문” 단정 금지.
•
상관 관계 기반 인사이트 수준에서 제안.
06. 데이터셋
데이터 다운로드
07. 예시 코드
1) 기본 로딩 & 구조 확인import pandas as pd
# 2018년 데이터 로드 (예시)
column_names = [
'RCPT_YR','CGG_CD','CGG_NM','STDG_CD','STDG_NM',
'LOTNO_SE','LOTNO_SE_NM','MNO','SNO','BLDG_NM',
'CTRT_DAY','THING_AMT','ARCH_AREA','LAND_AREA','FLR',
'RGHT_SE','RTRCN_DAY','ARCH_YR','BLDG_USG','DCLR_SE',
'OPBIZ_RESTAGNT_SGG_NM'
]
dtype_dict = {
'RCPT_YR':'int64','CGG_CD':'string','CGG_NM':'string',
'STDG_CD':'string','STDG_NM':'string',
'THING_AMT':'int64','ARCH_AREA':'float64','LAND_AREA':'float64'
}
df = pd.read_csv("2018.csv", encoding="euc-kr", names=column_names, dtype=dtype_dict, skiprows=1)
print("데이터 크기:", df.shape)
print(df.head())
print(df.isnull().sum())
Python
복사
2) 전처리 (결측치/이상치 처리)# 거래 취소 건 제거
df = df[df["RTRCN_DAY"].isna()]
# 거래금액 IQR 기반 이상치 제거
Q1 = df["THING_AMT"].quantile(0.25)
Q3 = df["THING_AMT"].quantile(0.75)
IQR = Q3 - Q1
lower, upper = Q1 - 1.5*IQR, Q3 + 1.5*IQR
df = df[(df["THING_AMT"] >= lower) & (df["THING_AMT"] <= upper)]
# 건축연도 정제
df["ARCH_YR"] = pd.to_numeric(df["ARCH_YR"], errors="coerce")
df = df[(df["ARCH_YR"] >= 1900) & (df["ARCH_YR"] <= pd.Timestamp.today().year)]
# 층 정제
df["FLR"] = pd.to_numeric(df["FLR"], errors="coerce")
df = df[df["FLR"].notna() & (df["FLR"] >= 0)]
# 계약일 처리
df["CTRT_DAY"] = pd.to_datetime(df["CTRT_DAY"], errors="coerce", format="%Y%m%d")
df["contract_year"] = df["CTRT_DAY"].dt.year
df["contract_month"] = df["CTRT_DAY"].dt.month
print("정제 후 데이터 크기:", df.shape)
Python
복사
3) 간단 EDA (기술통계 & 시각화)import matplotlib.pyplot as plt
# 자치구별 평균 거래금액 & 표준편차
gu_stats = df.groupby("CGG_NM")["THING_AMT"].agg(mean_price="mean", std_price="std").reset_index()
plt.figure(figsize=(12,6))
plt.bar(gu_stats["CGG_NM"], gu_stats["mean_price"], yerr=gu_stats["std_price"], capsize=5, color="skyblue")
plt.xticks(rotation=45)
plt.ylabel("거래금액 (만원)")
plt.title("자치구별 평균 거래금액 및 변동성")
plt.show()
Python
복사