

01. 개요


 미국 교통부 물류 데이터(FAF5.7.1)를 분석하여 국가 물류 인사이트를 도출해 보세요!
미국 교통부 물류 데이터(FAF5.7.1)를 분석하여 국가 물류 인사이트를 도출해 보세요!•
FAF(Freight Analysis Framework)는 미국 교통부(FHWA)와 교통통계국(BTS)이 구축한 국가 화물 운송 데이터베이스입니다.
•
이 데이터는 어디서(Origin) → 어디로(Destination), 무엇을(SCTG 품목), 어떻게(운송 모드), 얼마나(가치·톤수·톤마일) 운송했는지를 기록하고 있습니다.
•
분석가는 이를 통해 어떤 주(State)가 물류 허브인지, 어떤 산업군이 고부가가치/저중량 화물 중심인지, 도로운송 편중 구조가 어떤 의미를 가지는지 등 실제 정책·산업 전략에 필요한 인사이트를 도출합니다.
당신은 물류 분석 팀의 데이터 애널리스트입니다!•
물류 데이터를 탐색하여 운송 현황을 한눈에 보여주세요.
•
앞으로 물류 정책/관리의 방향이 어떻게 나아가야하는지 데이터 근거를 제시해주세요.
02. 배경
FAF 데이터의 맥락•
미국 내 물류는 트럭 중심(road-dominant) 구조를 보입니다. 하지만 철도·해상·항공도 각각 중요한 의미를 가지며, 특히 항공은 비중은 낮지만 고가품을 운송한다는 점에서 전략적 해석이 필요합니다.
•
글로벌 공급망 불안정성, 친환경 전환, 교통 인프라 투자가 동시에 진행되는 가운데, 화물의 흐름을 정량적으로 파악하는 데이터 기반 분석은 필수적입니다.
주요 이해 관계자 예시•
다음년도 예산 및 정책을 계획하는 도로교통부
•
화물운송의 트렌드를 확인하고 대비하고자 하는 운송업체 대표
•
미리 특정 허브에 특정 물건을 옮겨두어 리소스를 절약하고 싶은 커머스 업체 대표
03. 주제
“챠량 데이터에 대한 EDA를 진행하고 결과를 도출하는(보여주는) 것”으로 생각해주세요. •
데이터 EDA(Exploratory Data Analysis) 는 탐색적 데이터 분석을 의미합니다.
•
EDA 는 크게 이상치/결측치 처리 및 시각화 로 나뉩니다.
•
EDA 프로세스
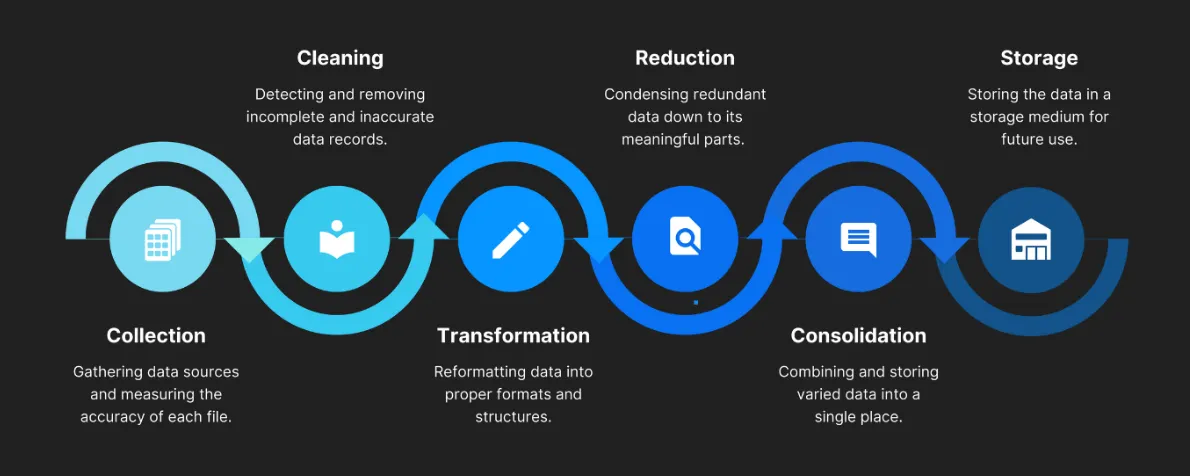 분석 목표
분석 목표•
데이터 EDA
•
데이터 정제 및 데이터 전처리
•
데이터 시각화 및 분석
•
데이터 기반 인사이트 도출
분석 결과물에 포함해야 할 내용•
비즈니스 목표
•
사용된 데이터 소스 설명
•
EDA 과정
•
전처리 과정
•
주요 분석제시 및 시각화
인사이트 제시
필수분석 목표•
[비즈니스 목표 세우기]
•
[사용된 데이터 소스 설명] 출처, 구성, 관측단위, 주요 변수를 소개하세요.
[EDA ]각 테이블의 행/열 개수를 제시하세요.
[EDA] 분석할 데이터의 컬럼 타입과 기술통계(min/median/mean/max, 결측치 수)를 제시하여 EDA를 수행하세요.
[전처리과정] 테이블 결합(merge)으로 분석용 단일 데이터셋을 만드세요.
[전처리과정] 결측치/이상치 처리 규칙을 수립·실행하고, 처리 이유를 적으세요.
[주요 분석제시 및 시각화] 한개 혹은 여러개의 기준 컬럼을 두고 집계함수로 비교분석 후 시각화하세요.
[인사이트 제시] 최소 1개 이상의 인사이트를 제시하세요.
심화 분석목표 예시위의 필수분석목표들을 완료하고, 심화 분석을 원하는 학생에 한하여 선택적으로 수행합니다.
꼭 아래 문제들이 아니라, 풀고싶은/보여주고 싶은 분석과 인사이트를 보여주셔도 됩니다!
•
EDA를 더 다양한 형식(산점도, 박스플롯 등)으로 나타내보기
•
분석할 데이터를 설명할때 ERD 보여주기
•
2개 이상의 기준을 둔 다차원 비교(예: sctg2 × dms_mode 피벗 테이블)
◦
예: 행=품목, 열=모드, 값=value_2024 합 → 피벗·히트맵으로 표현
•
연도별 성장률(YoY) 계산 및 Top 성장 품목/주 도출
•
거리구간(dist_band)별 패턴 비교(근거리 vs 장거리)
◦
dist_band를 묶어(예: 1–2=근거리, 3–5=중거리, 6–8=장거리) 평균 톤·가치 비교
•
Top-OD 히트맵(상위 N개 주만 사용)
◦
전체 OD 행렬은 너무 크므로 상위 8~10개 주로 축소해 히트맵을 그리면 가독성이 좋습니다.
•
국내운송의 특징과 국제운송의 특징을 보여주세요.
•
연도별 모드 점유율 합계가 ≈100%인지 확인하시면 전처리 이상 유무를 빠르게 점검할 수 있습니다. 왜 그런지 설명하고 해당 설명을 바탕으로 이상치 처리를 해보세요.
04. 설명
데이터 개요•
관측 단위: 출발지(Origin) → 도착지(Destination) × 품목(SCTG2) × 운송 모드 × 거래유형 × 거리구간 × 연도
•
시간 범위(현재 파일): 2018–2024
•
주요 측정값
◦
물동량: tons_YYYY
◦
가치(실질): value_YYYY (2017년 불변가격)
◦
가치(명목): current_value_YYYY (해당 연도 명목가격)
◦
거리×물동량: tmiles_YYYY (톤마일)
기본 EDA에서는 OD·모드·품목·연도 축을 중심으로 집계/비교하시면 됩니다.
핵심 지표 단위•
tons_YYYY = 천 톤(Thousand Tons)
•
value_YYYY = 백만 달러(Million USD, 2017 불변)
•
current_value_YYYY = 백만 달러(Million USD, 명목)
•
tmiles_YYYY = 백만 톤마일(Million Ton-miles)
성장률·장기 추세 비교는 불변가(value_*) 사용을 권장,
해당연도 분배/시장규모 감각은 **명목(current_value_*)**가 해석이 쉽습니다.
데이터 상세사항 안내
도메인 가이드•
톤마일(ton-miles): “화물 중량 × 이동 거리” 지표. → 운송 부담·환경 영향 해석에 활용.
•
SCTG 코드: 북미 산업 분류 체계(NAICS) 기반 품목 분류. 예: 02 곡물, 17 휘발유, 20 화학제품.
•
항공 모드: 점유율은 극히 낮지만, 고가품 운송이라는 의미를 반드시 고려해야 합니다.
도움이 되는 분석 포인트•
가치(Value) vs 중량(Tons)은 서로 다른 시각을 제공하므로 함께 분석
•
운송 모드는 국내 구간(dms_mode)을 중심으로 보되, 국제 교역의 경우 fr_inmode·fr_outmode도 참고
•
항공(air)은 비중이 낮아 단순 분포 비교시 무의미하게 보일 수 있으므로, “항공=소량·고가품”이라는 도메인 지식이 필요합니다.
•
주 단위 집계 시에는 데이터가 안정적이지만, 세부 지역 코드(FAF Zone) 데이터는 60% 이상 결측치가 발생합니다. 따라서 실습에서는 주 단위 흐름을 중심으로 분석하는 것이 권장됩니다.
05. 데이터셋
데이터 다운로드아래 원본 데이터를 기반으로 양을 절반으로 줄이고 오류 수정한 버전이니, 위의 FAF5.7.1_2018-2024_half.csv를 쓰시면 됩니다.
원본 데이터 출처

06. 참고사항
1.
세그먼트 이중집계 주의
•
국제 흐름은 “국내 구간(dms_mode)”과 “국경 밖 구간(fr_inmode/fr_outmode)”이 동시에 존재할 수 있습니다.
•
기본 EDA에서는 dms_mode만 사용하시거나, 국제 분석 시 어느 세그먼트를 볼지(입경/출경 vs 국내) 명시하세요.
•
trade_type으로 서브셋을 나누면 안전합니다. (예: Domestic만 보면 fr_* 결측이 정상)
2.
불변 vs 명목 가치 선택
•
년간 성장/추세 비교: value_*(2017 불변)
•
해당연도 점유율/시장규모: current_value_*(명목)
3.
단위 스케일
•
tons_*는 천 톤, value_*/current_value_*는 백만 달러, tmiles_*는 백만 톤마일입니다.
•
그래프 축/범례/캡션에 반드시 단위를 표기해 혼동을 방지해야합니다.
4.
거리 해석(국제)
•
수입(Import)은 입경 지점 → 미 국내 도착, 수출(Export)은 미 국내 출발 → 출경 지점 구간을 기준으로 dist_band가 정해져요.
5.
FAQ
•
Q. value_*와 current_value_*가 둘 다 있는데 무엇을 써야 하나요?
A. 추세/성장률은 불변가(value_*), 해당연도 비중/규모는 **명목가(current_value_*)**가 적합해요.
•
Q. Import/Export를 합쳐 International로 보고 싶습니다.
A. trade_type가 2 또는 3인 행을 묶어 International로 라벨링해서 쓰세요.
•
Q. 모드 비중을 그릴 때 어떤 모드를 써야 정확한가요?
A. 국내 구간 분석이면 dms_mode만 사용하십시오. 국제 루트를 나눠 보고 싶다면 fr_inmode(수입)·fr_outmode(수출)를 별도 차트로 제시하세요.
•
Q. Top-OD를 구할 때 단위는 무엇으로 할까요?
A. 전략 목적에 맞게 선택합니다. 시장성/가치 흐름은 value_*/current_value_*, 물량/물류 운영은 tons_*가 적합합니다.
07. 예시 코드
공통설정 및 기본 정보 확인(예시)# 공통 임포트 및 설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 1) 데이터 로드 및 로딩 직후 정보 확인
df = pd.read_csv("FAF5.7.1_2018-2024_half.csv")
print("원시 shape:", df.shape)
print("\n컬럼 타입 분포:")
print(df.dtypes.value_counts())
print("\n상위 20개 결측치 개수:")
print(df.isna().sum().sort_values(ascending=False).head(20))
print("\n샘플(상위 5행):")
print(df.head().to_string(index=False))
Python
복사
메타 매핑 합치기 (예시)import pandas as pd
df = pd.read_csv("FAF5.7.1_2018-2024_half.csv")
# 메타 로드
meta = "FAF5_metadata.xlsx"
mode = pd.read_excel(meta, sheet_name="Mode").rename(columns={"Numeric Label":"code","Description":"mode_name"})
trade = pd.read_excel(meta, sheet_name="Trade Type").rename(columns={"Numeric Label":"code","Description":"trade_name"})
dist = pd.read_excel(meta, sheet_name="Distance Band").rename(columns={"Numeric Label":"code","Description":"dist_name"})
sctg = pd.read_excel(meta, sheet_name="Commodity (SCTG2)").rename(columns={"Numeric Label":"code","Description":"sctg2_name"})
# 조인(모드/거래/거리/품목)
df = df.merge(mode[["code","mode_name"]], left_on="dms_mode", right_on="code", how="left").drop(columns="code")
df = df.merge(trade[["code","trade_name"]], left_on="trade_type", right_on="code", how="left").drop(columns="code")
df = df.merge(dist[["code","dist_name"]], left_on="dist_band", right_on="code", how="left").drop(columns="code")
df = df.merge(sctg[["code","sctg2_name"]], left_on="sctg2", right_on="code", how="left").drop(columns="code")
# 국제 여부 파생
df["intl_flag"] = df["trade_type"].isin([2,3]).map({True:"International", False:"Domestic"})
Python
복사
Domestic / International 모드 선택 방식(혼합 실수 방지) (예시)•
Domestic과 International의 모드 컬럼이 다릅니다(dms_mode vs fr_inmode/fr_outmode). 혼합하면 합계가 맞지 않습니다. (보통 보고서는 Domestic만 별도 분석하고 국제 흐름은 따로 요약하는 것이 안전합니다.)
•
간단 규칙:
◦
Domestic → dms_mode
◦
Import → fr_inmode
◦
Export → fr_outmode
•
합쳐서 확인하고 싶을 때(권장: 분리 검증 후 합치기):
def pick_mode(row):
if row['trade_type'] == 1:
return row['dms_mode']
if row['trade_type'] == 2:
return row['fr_inmode']
if row['trade_type'] == 3:
return row['fr_outmode']
return np.nan
val_long['mode_for_analysis'] = val_long.apply(pick_mode, axis=1)
mode_all = val_long.groupby(['year','mode_for_analysis'], as_index=False)['value_musd'].sum()
mode_all['share'] = mode_all['value_musd'] / mode_all.groupby('year')['value_musd'].transform('sum')
Python
복사
연도별 총합(가치/중량) 추세 시각화 (예시)val_cols = [c for c in df.columns if c.startswith("value_")]
tons_cols = [c for c in df.columns if c.startswith("tons_")]
total_value = df[val_cols].sum()
total_value.index = total_value.index.str.split("_").str[-1].astype(int)
total_tons = df[tons_cols].sum()
total_tons.index = total_tons.index.str.split("_").str[-1].astype(int)
fig, ax = plt.subplots(1,2,figsize=(14,4))
total_value.sort_index().plot(ax=ax[0], marker='o', title="Yearly Total Value (2017 constant, M USD)")
ax[0].set_ylabel("Million USD (2017)")
total_tons.sort_index().plot(ax=ax[1], marker='o', title="Yearly Total Tons (Thousand Tons)")
ax[1].set_ylabel("Thousand Tons")
plt.tight_layout()
plt.show()
Python
복사
0 또는 NaN으로 나눌 때(단위당 값 계산) 안전하게 처리하기 (예시)•
value_per_ton = value / tons 계산은 division-by-zero과 무한대 문제를 자주 만듭니다.
grp['value_per_ton'] = grp['value_2024_sum'] / grp['tons_2024_sum'].replace({0: np.nan})
grp['value_per_ton'] = grp['value_per_ton'].replace([np.inf, -np.inf], np.nan)
# 필요하면 0으로 채우거나 상위 N%만 사용해서 라벨링
grp['value_per_ton'] = grp['value_per_ton'].fillna(0)
Python
복사
위와 같은 코드를 통해 안전하게 처리할 수 있습니다.
•
팁: 0으로 채운 후 상위 퍼센타일로 고가품을 뽑으면 0 채운 항목 영향 없음(안정적).
IQR를 활용한 이상치 처리 (예시. 이상치 처리 방법 중 하나입니다.)IQR로 이상치 검출 후 라벨만 붙이고 제거는 신중하게 해야 합니다(원인 파악 우선).
q1 = df['value_2024'].quantile(0.25)
q3 = df['value_2024'].quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5*iqr
upper = q3 + 1.5*iqr
df['value_2024_iqr_outlier'] = ~df['value_2024'].between(lower, upper)
print("IQR 이상치 개수:", df['value_2024_iqr_outlier'].sum())
Python
복사
권장 절차: 이상치 발견 → 샘플 몇 개 직접 원데이터/메타 확인 → 원인(합계누락/환율문제/데이터 입력 오류) 규명 → 보고서에 처리 규칙 기재.