


민정튜터님께 이 사람은 못바쳐도 이 사진을 바칩니다
01. 개요
 폭발적으로 성장하는 게임 도메인은 ‘작은 사회’와 같습니다.
폭발적으로 성장하는 게임 도메인은 ‘작은 사회’와 같습니다.•
전 세계 게임 시장의 규모는 2023년 기준 약 4,062억 달러에 달하며, 매년 꾸준한 성장률을 기록하고 있습니다. Source: Statista(2024)
•
사용자들은 ‘작은 사회’에서 다양한 행동을 취하며 즐거움을 얻습니다. 예시로 PVP, PVE, 요리, 낚시, 무기강화, 뽑기, 출석체크, 코스튬 장착, 펫 장착 등이 있습니다.
•
데이터분석가는 위와 같은 행동·전투·성장 데이터를 통해 문제를 정의하고, 가설을 세워 검증하며, 서비스 개선 인사이트(솔루션)를 제안합니다.
당신은 라이엇게임즈에서 ‘롤토체스’를 담당한 데이터 애널리스트입니다!. •
게임 데이터를 탐색하여 서비스 현황을 한눈에 보여주세요.
•
우리 서비스가 앞으로 어떤 방향으로 나아가야 하는지 데이터 근거를 제시해주세요.
02. 배경
’롤토체스’란?•
TFT(Teamfight Tactics, 일명 롤토체스)는 PC 게임 생태계에서 중요한 콘텐츠로, 자동전투(Auto Battler) 장르를 대표합니다.
•
TFT는 8인 개인전, 1라운드 ≈ 1분, 총 15–30분의 세션으로 구성됩니다.
•
플레이어들은 약 1분마다 상대 플레이어 및 몬스터와 싸우게 되고, 이를 통해 돈이나 아이템을 얻고 챔피언(영웅)을 구입하여 조합을 맞춰나가야 합니다.
•
한 경기에서 패배 시 플레이어의 체력이 달며, 체력이 0이 되면 최종 패배하게 됩니다.
롤토체스의 도메인 지식•
시너지(Combination): 특정 챔피언을 모아 세트 효과를 발동시키는 구조. 예를 들어, 3명의 ‘마법사’ 조합 시 추가 주문력이 부여됨.
•
챔피언 특성: 코스트(1~5골드), 체력, 공격력, 공격 속도, DPS 등이 승률에 직접적인 영향을 줌.
•
티어(Tier): 플레이어 숙련도를 보여주는 구간(Challenger, GrandMaster, Master, Diamond, Platinum). 티어별 메타 채택률이 다르고, 상위 티어ほど 최적화된 빌드를 빠르게 도입하는 경향이 있음.
•
게임 지표: Ranked(1~8위), lastRound, gameDuration, ingameDuration 등은 플레이 효율과 생존력의 핵심 지표.
주요 이해 관계자 예시•
라이엇 밸런스 팀: 어떤 조합이나 챔피언이 과도하게 강력한지 확인
•
서비스 기획자: 신규 시즌 콘텐츠 기획 시, 기존 데이터 기반으로 개선 포인트 도출
•
유저 커뮤니티: “어떤 조합이 지금 메타에서 강한가?” 같은 질문에 객관적 수치 제공
03. 주제
“TFT(LOL) 데이터에 대한 EDA 를 진행하고 결과를 도출하는(보여주는) 것”으로 생각해주세요. •
데이터 EDA(Exploratory Data Analysis) 는 탐색적 데이터 분석을 의미합니다.
•
EDA 는 크게 이상치/결측치 처리 및 시각화 로 나뉩니다.
•
EDA 프로세스
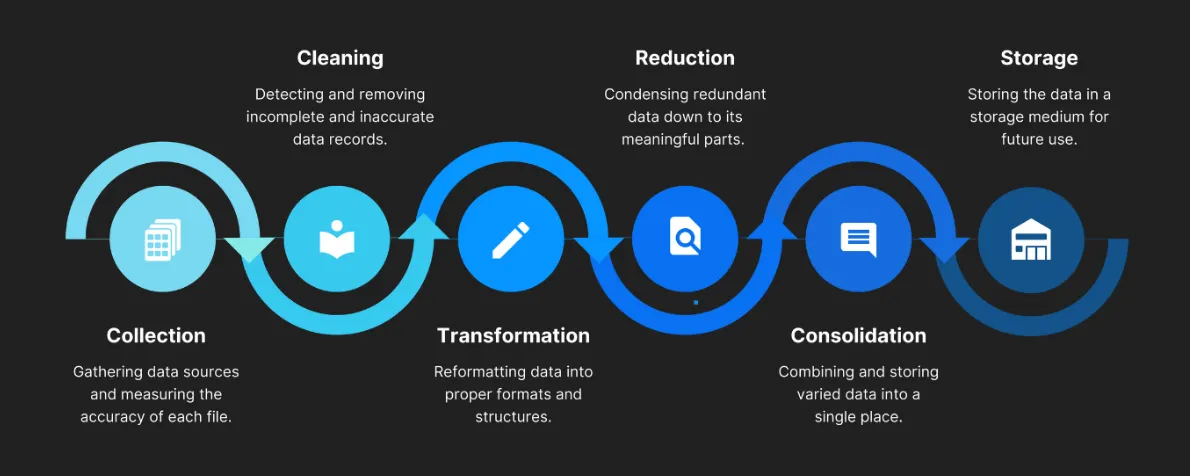 분석 흐름 개요
분석 흐름 개요•
데이터 EDA
•
데이터 정제 및 데이터 전처리
•
데이터 시각화 및 분석
•
데이터 기반 인사이트 도출
필수 분석 목표[비즈니스 목표 세우기]
[사용된 데이터 소스 설명] 출처, 구성, 관측단위, 주요 변수를 소개하세요.
[EDA] 분석할 데이터의 행/열 개수를 제시하세요.
[EDA] 분석할 데이터의 컬럼 타입과 기술통계(min/median/mean/max, 결측치 수)를 제시하여 EDA를 수행하세요.
[전처리] 테이블 결합으로 분석용 단일 데이터셋을 만드세요.
[전처리 과정] 결측치/이상치/전처리 처리 규칙을 수립·실행하고, 처리 이유를 적으세요.
[주요 분석제시 및 시각화] 하나 이상의 기준 컬럼을 두고 집계함수로 비교분석 후 시각화하세요
[인사이트 제시] 최소 1개 이상의 인사이트를 수치/그래프/그림/해석으로 제시하세요.
심화 분석 목표필수 분석 이후 더 도전하고 싶은 학생들을 위한 심화 과제입니다. (선택 과제)
꼭 아래 문제들이 아니라, 풀고싶은/보여주고 싶은 분석과 인사이트를 보여주셔도 됩니다!
•
EDA를 더 다양한 형식(산점도, 박스플롯 등)으로 나타내보기
•
분석할 데이터를 설명할때 ERD 보여주기
파생변수를 활용하여 조합별(조합 문자열 기준) 사용 빈도와 Top4 비율(성공률)을 계산해, 자주 쓰이지만 성과가 낮은 조합 / 희귀하지만 성과가 높은 조합을 찾습니다.
챔피언 비용(예: 1~5) 또는 팀의 평균 cost(조합당 평균 cost)와 게임 성적(평균 Rank, Top4 비율) 간 관계를 확인합니다.
•
조합을 영웅으로 분리하여 영웅 기여도/특성(코스트·DPS 등)과 성과의 관계 분석
•
흔하게 함께 사용되는 아이템 쌍(또는 트리오)을 찾고, 그 조합을 장착한 게임들의 평균 Rank/Top4 비율을 비교합니다.
•
게임 시간대별(예: <10분 / 10–20 / >20) 성과 차이 분석. 특정 조합이나 챔피언이 빠른 게임에서 성과가 좋은지 확인.
•
사용자(Id)별로 사용한 조합의 수(또는 챔피언 조합 다양성)를 계산해, 다양성이 높을수록 평균 성적이 어떤지 확인.
•
Challenger~Platinum 등 티어별로 선호 조합/챔피언/아이템이 다른지 비교.
04. 설명
데이터 개요•
총 7개 CSV 파일
◦
챔피언 정보: TFT_Champion_CurrentVersion.csv
◦
아이템 정보: TFT_Item_CurrentVersion.csv
◦
티어별 매치 데이터: TFT_Challenger_MatchData.csv, TFT_GrandMaster_MatchData.csv, TFT_Master_MatchData.csv, TFT_Diamond_MatchData.csv, TFT_Platinum_MatchData.csv
•
관측 단위: 플레이어–게임 (한 게임에서 8명의 참가자가 각각 1행으로 기록됨)
•
데이터 크기
◦
티어별 수천~수만 행 (총 수십만 행 이상)
◦
챔피언/아이템 테이블은 수십 행 수준 (챔피언 약 60명, 아이템 약 30종)
데이터 특성챔피언 데이터
아이템 데이터
매치 데이터(티어별)
ERD 데이터 상세사항 도메인 가이드•
Ranked(순위): 1~8위 → 통상 Top4(상위권 진입률) 지표를 사용
•
lastRound: 최종 생존 라운드 수 → 조합 안정성 지표
•
combination: 시너지 발동 구조, 메타 분석의 핵심
•
champion: 개별 챔피언 성능 → 조합 단위 분석과 결합 가능
•
티어별 비교: 상위 티어ほど 메타 적응 속도가 빠르므로, 동일 조합이라도 성과 차이가 발생할 수 있음
05. 데이터

06. 참고 사항
•
결측치·이상치 처리
◦
Ranked가 1~8 범위를 벗어나거나, gameDuration이 5분 이하/1시간 이상인 경우는 이상치일 가능성이 큽니다.
◦
champion과 combination은 쉼표 구분 문자열이라 누락/불일치(챔피언 이름 오타 등)가 발생할 수 있습니다.
•
문자열 파싱 주의
◦
combination과 champion 컬럼은 반드시 분리(split → explode) 후 사용해야 합니다.
◦
파싱 과정에서 공백·대소문자 차이로 매칭이 실패할 수 있으므로, 정규화(normalization) 과정을 거쳐야 합니다.
•
티어별 데이터 규모 차이
◦
Challenger/Master 티어는 표본 수가 작고, Platinum/Diamond는 훨씬 큽니다.
◦
따라서 티어 비교 시 반드시 비율(%) 기준으로 해석해야 합니다.
•
시간 지표 해석
◦
gameDuration과 ingameDuration의 불일치가 발생할 수 있습니다. 이는 데이터 수집 과정 특성으로,
플레이어 탈락 시점과 전체 게임 종료 시점의 차이를 반영합니다.
•
지표 해석 시 주의
◦
특정 조합의 높은 승률이 곧 “OP(Overpowered)”를 의미하는 것은 아닙니다.
◦
플레이어의 숙련도, 티어별 선택 편향, 샘플 수 차이가 영향을 줄 수 있으므로, 원인 단정은 금물입니다.
•
FAQ
◦
Q. 조합을 하고 싶은데, 조합이 너무 많아 분석이 어렵습니다.
A. 빈도 상위 20~30개 조합을 중심으로 분석하고, 희귀 조합은 “기타”로 묶는 것을 권장합니다.
◦
Q. 챔피언 이름이 안 맞아서 조인이 안 됩니다.
A. Champion.name과 매치 데이터의 champion 컬럼을 소문자 변환·트림(strip) 처리 후 매핑하세요.
◦
Q. Top4 비율만 보면 충분한가요?
A. 평균 순위, 표준편차, Bottom4 비율까지 함께 제시해야 조합의 안정성을 해석할 수 있습니다.
07. 예시 코드
기본 로딩 & 구조 확인import pandas as pd
# 챔피언 데이터
champ = pd.read_csv("TFT_Champion_CurrentVersion.csv")
print("Champion shape:", champ.shape)
print(champ.dtypes)
# 티어별 매치 데이터 불러오기 (예시: Challenger)
challenger = pd.read_csv("TFT_Challenger_MatchData.csv")
print("Challenger shape:", challenger.shape)
print(challenger.head())
Python
복사
다중 파일 통합 & 티어 정보 추가import glob
# 티어별 파일 경로 패턴
files = glob.glob("TFT_*_MatchData.csv")
dfs = []
for f in files:
tier = f.split("_")[1] # 파일명에서 티어 추출
temp = pd.read_csv(f)
temp["tier"] = tier
dfs.append(temp)
match = pd.concat(dfs, ignore_index=True)
print("Match dataset shape:", match.shape)
Python
복사
파생 지표 생성# 순위 그룹화
match["Top4"] = (match["Ranked"] <= 4).astype(int)
# 조합/챔피언 문자열 분해 → explode
match["champion_list"] = match["champion"].str.split(",")
match_exploded = match.explode("champion_list").rename(columns={"champion_list": "champion_name"})
# 챔피언 데이터와 조인
merged = match_exploded.merge(champ, left_on="champion_name", right_on="name", how="left")
Python
복사
간단 EDA 예시import matplotlib.pyplot as plt
# 티어별 평균 순위
tier_rank = match.groupby("tier")["Ranked"].mean().sort_values()
tier_rank.plot(kind="bar", title="Average Rank by Tier")
plt.ylabel("Average Rank")
plt.show()
# 조합별 Top4 비율 (상위 10개)
comb_top4 = match.groupby("combination")["Top4"].mean().sort_values(ascending=False).head(10)
comb_top4.plot(kind="barh", title="Top4 Rate by Combination (Top 10)")
plt.xlabel("Top4 Rate")
plt.show()
# 챔피언 코스트별 평균 순위
cost_rank = merged.groupby("cost")["Ranked"].mean()
cost_rank.plot(marker="o", title="Average Rank by Champion Cost")
plt.ylabel("Average Rank")
plt.show()
Python
복사