


01. 개요
 H&M 고객·매출 데이터를 분석하여 커머스 인사이트를 도출해 보세요!
H&M 고객·매출 데이터를 분석하여 커머스 인사이트를 도출해 보세요!•
H&M은 1947년 설립되어 전 세계 70여 개국에서 의류, 홈, 뷰티, 아동 의류를 판매하는 대표적인 패션 기업입니다.
•
제공된 데이터는 고객(customers_hm), 거래(transactions_hm), 상품(articles_hm)을 기록한 대규모 커머스 데이터셋입니다.
•
고객, 매출분석은 커머스 뿐만 아니라 도메인을 아울러 가장 기본적이고 필수적인 부분입니다.
•
분석가는 이를 통해 고객 세그먼트별 매출 특징, 상품군별 트렌드, 온라인/오프라인 채널 편중 구조 등 실제 전략 수립에 필요한 인사이트를 도출해야 합니다.
당신은 H&M 데이터 분석 팀의 데이터 애널리스트입니다!•
고객·매출 데이터를 활용해 서비스 현황을 점검하고,
•
앞으로 H&M의 고객 경험 개선과 매출 성장 전략에 기여할 수 있는 결과물을 만들어야 합니다.
02. 배경
H&M 데이터 분석 맥락•
글로벌 이커머스 시장은 2024년 6.3조 달러 규모, 2027년에는 8조 달러에 근접할 전망입니다. 이 중 의류/패션잡화는 약 23%를 차지하며 7천억 달러 규모로 성장할 것으로 예상됩니다.
•
모바일 구매 비중은 56.7%로, PC 대비 약 13.8%p 높게 나타나고 있습니다.
•
고객의 기본 속성(나이, 성별, 멤버십 상태 등)과 행태 데이터(구매일, 가격, 채널, 상품 속성 등)는 커머스 인사이트의 핵심입니다.
•
따라서 H&M 데이터셋은 고객 세분화, 구매 패턴 탐색, 상품군 분석을 동시에 수행할 수 있습니다.
이번 프로젝트 요청사항•
고객·매출 데이터를 탐색하여 서비스 현황을 시각화해 주세요.
•
채널/상품군/고객 속성별 매출 특징을 분석해 주세요.
•
이상치/결측치 처리 과정을 포함한 탐색적 데이터 분석(EDA) 결과를 제출해 주세요.
•
분석 결과 및 인사이트(전략)을 제공해주세요.
주요 이해관계자 예시•
H&M 마케팅팀: 고객 세그먼트별 프로모션 전략
•
상품기획팀: 인기 상품군 및 색상·카테고리 트렌드
•
경영진: 온라인·오프라인 채널 매출 구조 및 성장 가능성
03. 주제
“커머스 고객/매출 데이터에 대한 EDA 를 진행하고 결과를 도출하는(보여주는) 것”으로 생각해주세요. •
데이터 EDA(Exploratory Data Analysis) 는 탐색적 데이터 분석을 의미합니다.
•
EDA 는 크게 이상치/결측치 처리 및 시각화 로 나뉩니다.
•
EDA 프로세스
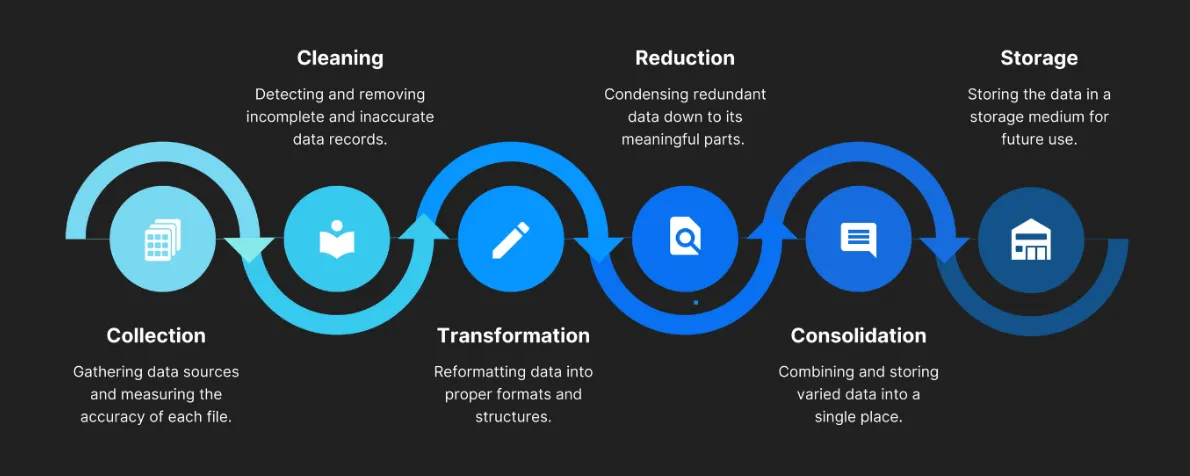 분석 흐름 개요
분석 흐름 개요•
데이터 EDA
•
데이터 정제 및 전처리
•
데이터 시각화 및 분석
•
데이터 기반 인사이트 도출
필수 분석 목표[비즈니스 목표 세우기]
[사용된 데이터 소스 설명] 출처, 구성, 관측단위, 주요 변수를 소개하세요.
[EDA] 분석할 데이터의 행/열 개수를 제시하세요.
[EDA] 분석할 데이터의 컬럼 타입과 기술통계(min/median/mean/max, 결측치 수)를 제시하여 EDA를 수행하세요.
[전처리] 테이블 결합으로 분석용 단일 데이터셋을 만드세요.
[전처리 과정] 결측치/이상치/전처리 처리 규칙을 수립·실행하고, 처리 이유를 적으세요.
[주요 분석제시 및 시각화] 하나 이상의 기준 컬럼을 두고 집계함수로 비교분석 후 시각화하세요
[인사이트 제시] 최소 1개 이상의 인사이트를 수치/그래프/그림/해석으로 제시하세요.
심화 분석 목표필수 분석 이후 더 도전하고 싶은 학생들을 위한 심화 과제입니다. (선택사항)
꼭 아래 문제들이 아니라, 풀고싶은/보여주고 싶은 분석과 인사이트를 보여주셔도 됩니다!
•
EDA를 더 다양한 형식(산점도 등)으로 나타내보기
고객별 총 구매액을 기준으로 상위 20% / 하위 20% 그룹을 만들어 주요 지표(평균 구매액, 구매 빈도, 채널 비중 등)를 비교
전체/고객별 월별 시계열에 3개월(또는 6개월) 롤링 평균을 적용해 노이즈 제거된 매출 추세를 시각화
가격 분포가 한쪽으로 치우쳐 있으므로 로그 변환(log-scale) 혹은 정규화(z-score, Min-Max)를 적용해 고객·상품군 간 구매액 분포를 비교
월별/분기별 평균 매출을 계산해 장기 추세(증가·감소)와 시즌성(예: 블랙프라이데이, 연말연시 등)을 파악
이상치 고객·거래 탐색 전략
고객 속성 × 채널 교차분석
확장 데이터 조인
•
여러 테이블(csv파일)을 활용하여 분석한다면, 데이터 설명시 ERD도 보여주기
위 결과들을 바탕으로 H&M 고객 경험 개선 전략 제안
04. 설명
데이터 개요•
관측 단위: 고객–거래–상품 결합
•
주요 테이블 (총 3개의 CSV 파일)
◦
customers_hm: 고객 ID, 성별, 연령, 클럽 상태, 뉴스 구독 여부
◦
transactions_hm: 거래일, 고객 ID, 상품 ID, 가격, 채널
◦
articles_hm: 상품 ID, 상품명, 카테고리, 색상, 상세 설명
•
기간: 수년간 기록된 고객 거래 데이터
테이블 관계 (ERD) 데이터 상세사항 안내
데이터 상세사항 안내05. 참고 사항
1.
결측치·이상치 처리
•
age: 0세·120세 등 비현실적 값 존재 가능. 제거 vs 대체 전략을 반드시 명시하세요. 연령대 파생(10대, 20대…) 시 극단치 제거가 선행되어야 합니다.
•
price: 0원 혹은 극단적 고액 값이 등장할 수 있습니다. 무료배포, 오류 입력, 환불 건 등 다양한 해석이 가능하므로 그대로 두거나 별도 플래그 처리 후 해석을 제시하세요.
•
club_member_status: 탈퇴 고객(LEFT CLUB)은 분석 대상에 포함할지 여부를 명확히 정해야 합니다.
2.
조인 전략
•
Inner Join: transactions_hm 중심으로 고객·상품 테이블을 결합할 때 기본 선택입니다. 단, 가입했으나 구매 이력이 없는 고객을 살피려면 Left Join이 필요할 수 있습니다.
•
조인 키 중복 주의: article_id 기준으로 결합 시 상품명·대분류 정보 중복 가능성이 있으니, 불필요한 중복 컬럼은 제거하세요.
3.
매출 계산 및 해석
•
transactions_hm에는 수량(quantity) 정보가 없습니다. 따라서 price를 곧바로 매출액으로 해석해야 하며, “구매 단가 총합”임을 명확히 적어야 합니다.
•
통화 단위(SEK, 스웨덴 크로나)임을 언급하세요. 달러나 원화로 혼동하면 안 됩니다.
•
인플레이션이나 연도별 환율 차이는 반영되지 않았으므로 절대적 추세 해석은 제한적입니다. 상대적 비교에 초점을 맞추세요.
4.
시간 단위 주의
•
t_dat는 거래일(YYYY-MM-DD)입니다.
→ 월별, 요일별 파생 컬럼을 생성할 때 반드시 datetime으로 변환하세요.
•
시즌성(예: 블랙프라이데이, 연말연시) 이벤트가 반영되어 있을 수 있으므로, 특정 월의 이상 급증을 “성장”으로 단정하지 마세요.
5.
데이터 편향 및 샘플링 한계
•
고객 데이터는 H&M 전체 이용자가 아니라 Kaggle에서 공개된 특정 표본입니다. “대표성 있는 인구 집단”으로 일반화하기에는 한계가 있습니다.
•
온라인 채널(sales_channel_id=2)의 기록이 상대적으로 많을 수 있습니다. 표본 편향으로 인한 채널 비중 왜곡 가능성을 반드시 언급하세요.
6.
비즈니스 해석 관련
•
고객 연령대·성별별 구매 패턴 차이는 단순한 “원인”이 아니라 “관찰된 결과”입니다. 예를 들어 20대 여성 매출이 높다고 해서 ‘20대 여성을 집중 타깃으로 하라’는 전략 제언을 할 때는 인과 해석에 주의하세요.
•
색상·상품군 인기도 단순 매출 상위 ≠ “트렌드 선도”. 상품 공급량, 재고 정책, 프로모션 영향이 있을 수 있으니 해석할 때 보수적으로 접근하세요.
7.
FAQ
•
Q. 모든 테이블을 반드시 결합해야 하나요?
A. 아닙니다. 분석 목적에 따라 조인 범위를 조정하세요. 예: 고객 세그먼트 분석은 customers_hm+transactions_hm만으로 충분할 수 있습니다.
•
Q. 온라인/오프라인 매출 비중을 비교할 때 sample size 차이는 어떻게 처리하나요?
A. 비율(%) 혹은 고객당 평균 구매액(ARPU)으로 보정하세요.
•
Q. 가격 분포가 왜 이렇게 한쪽으로 치우쳤나요?
A. 패션 리테일 특성상 저가 티셔츠·양말 등 소품 비중이 높아 분포가 비대칭입니다. 로그 변환(log-scale) 시각화로 해석을 보조하세요.
05. 데이터
데이터셋 다운로드 원본 데이터셋 출처
06. 예시 코드
기본 로딩 & 구조 확인import pandas as pd
# 데이터 불러오기
customers = pd.read_csv("customers.csv")
transactions = pd.read_csv("transactions.csv")
articles = pd.read_csv("articles.csv")
# 상위 5행 확인
print(customers.head())
print(transactions.head())
print(articles.head())
# 결측치 확인
print(customers.isnull().sum())
print(transactions.isnull().sum())
print(articles.isnull().sum())
Python
복사
조인 & 전처리# 고객-거래-상품 조인
df = transactions.merge(customers, on="customer_id", how="inner")
df = df.merge(articles, on="article_id", how="inner")
# 날짜 처리
df["t_dat"] = pd.to_datetime(df["t_dat"])
df["year"] = df["t_dat"].dt.year
df["month"] = df["t_dat"].dt.month
df["weekday"] = df["t_dat"].dt.day_name()
Python
복사
간단 시각화 예시import matplotlib.pyplot as plt
# 채널별 매출 비중
channel_sales = df.groupby("sales_channel_id")["price"].sum()
channel_sales.plot(kind="bar", title="Sales by Channel")
plt.show()
# 연령대별 평균 구매액
df["age_group"] = (df["age"] // 10) * 10
age_sales = df.groupby("age_group")["price"].mean()
age_sales.plot(kind="line", marker="o", title="Average Spending by Age Group")
plt.show()
Python
복사